Robots txt запрет индексации папки. Как запретить индексацию нужных страниц
Присамостоятельном продвижении и раскрутке сайтаважно не только создание уникального контента или подборзапросов в статистике Яндекса (чтобы составитьсемантическое ядро), но и так же следует уделять должное внимание такому показателю, какиндексация сайта вЯндексеиГугле . Именно эти две поисковые системы доминируют в рунете и то, насколько полной и быстрой будет индексация вашего сайта в Яндексе и Гугле зависит весь дальнейший успех продвижения.
У нас с вами имеются в распоряжении два основных инструмента, с помощью которых мы можем управлять индексацией сайта в Гугле и Яндексе. Во-первых, это, конечно же, файлrobots.txt
, который позволит нам настроить запрет индексации всего того на сайте, что не содержит основного контента (файлы движка и дубли контента) и именно о robots.txt и пойдет речь в этой статье, но кроме robots.txt существует еще один важный инструмент для управления индексацией —карта сайта (Sitemap xml), о которой я уже довольно подробно писал в приведенной по ссылке статье.
Robots.txt — почему так важно управлять индексацией сайта в Яндексе и Гугле
Robots.txt и Sitemap xml (файлы позволяющие управлять индексацией сайта) очень важны для успешного развития вашего проект и это вовсе не голословное утверждение. В статье по Sitemap xml (см. ссылку выше) я приводил в пример результаты очень важного исследования по наиболее частым техническим ошибкам начинающих вебмастеров и там на втором и третьем месте (после не уникального контента) находятся как разrobots.txt и Sitemap xml , а точнее либо отсутствие этих файлов, либо их неправильное составление и использование.
Надо очень четко понимать, что не все содержимое сайта (файлы и директории), созданного на каком-либо движке (CMS Joomla,SMFилиВордпресс), должно быть доступно для индексации Яндексом и Гугле (другие поисковые системы я не рассматриваю, в силу их малой доли в поиске рунета).
Если не прописать определенные правила поведения в robots.txt дляботов поисковых систем, то при индексации в поисковые системы попадет множество страниц, не имеющих отношения к содержимому сайта, а также может произойти многократное дублирование контента информации (по разным ссылкам будет доступен один и тот же материал сайта), что поисковики не любят. Хорошим решением будет запрет индексации в robots.txt.
Для того, чтобы задать правила поведения для поисковых ботов используется файл robots.txt . С его помощью мы сможем влиять на процесс индексации сайта Яндексом и Google. Robot.txt представляет из себя обычный текстовый файл, который вы сможете создать, и в дальнейшем редактировать, в любом текстовом редакторе (например,Notepad++). Поисковый робот будет искать этот файл в корневом каталогевашего сайта и если не найдет, то будет индексировать все до чего сможет дотянуться.
Поэтому после написания требуемого файла robots.txt (все буквы в названии должны быть в нижнем регистре — без заглавных букв) его нужно сохранить в корневую папку сайта, например, с помощьюFtp клиента Filezilla, так чтобы он был доступен по такому адресу: http://vash_site.ru/robots.txt.
Кстати, если вы хотите узнать как выглядит файл robots.txt того или иного сайта, то достаточно будет дописать к адресу главной страницы этого сайта /robots.txt . Это может быть полезно для определения наилучшего варианта для вашего файла robots.txt, но при этом надо учитывать, что для разных сайтовых движков оптимальный файл robots.txt будет выглядеть по разному (запрет индексации в robots.txt нужно будет делать для разных папок и файлов движка). Поэтому если вы хотите определиться с лучшим вариантом файла robots.txt>, допустим для форума на SMF, то и изучать файлы robots.txt нужно для форумов, построенных на этом движке.
Директивы и правила написания файла robots.txt (disallow, user-agent, host)
Файл robots.txt имеет совсем не сложный синтаксис, который очень подробно описан, например, в Я ндексе. Обычно, в файле robots.txt указывается для какого поискового робота предназначены описанные ниже директивы (директива"User-agent" ), сами разрешающие ("Allow ") и запрещающие директивы ("Disallow "), а также еще активно используется директива "Sitemap " для указания поисковикам, где именно находится файл карты сайта.
Еще полезно указать в файле robots.txt какое из зеркал вашего сайта является главнымв директиве "Host ". Если даже у вашего сайта нет зеркал, то полезно будет указать в этой директиве, какой из вариантов написания вашего сайта является главным с www или без него. Т.к. это тоже является своего рода зеркалированием. Об этом я подробно рассказывал в этой статье:Домены с www и без www — история появления, использование 301 редиректа для их склеивания.
Теперь поговорим немного оправилах написания файла robots.txt . Директивы в файле robots.txt имеют следующий вид:
Правильный файл robots.txt должен содержать хотя бы одну директиву «Disallow» после каждой записи «User-agent». Пустой файл robots.txt предполагает разрешение на индексирование всего сайта.
Директива «User-agent» должна содержать название поискового робота. При помощи этой директивы в robots.txt можно настроить индексацию сайта для каждого конкретного поискового робота (например, создать запрет индексации отдельной папки только для Яндекса). Пример написания директивы «User-agent», адресованной всем поисковым роботам зашедшим на ваш ресурс, выглядит так:
Приведу несколько простых примеровуправления индексацией сайта в Яндексе , Гугле и других поисковиках с помощью директив файла robots.txt с объяснением его действий.
- 1
. Приведенный ниже код для файла robots.txt разрешает всем поисковым роботам проводить индексацию всего сайта без каких-либо исключений. Это задается пустой директивой Disallow.
3 . Такой файл robots.txt будет запрещать всем поисковикам проводить индексацию содержимого каталога /image/ (http://mysite.ru/image/ — путь к этому каталогу)
5 . При описании путей для директив Allow-Disallow можно использоватьсимволы "*" и "$" , задавая, таким образом, определенные логические выражения. Символ "*" означает любую (в том числе пустую) последовательность символов. Следующий пример запрещает всем поисковикам индексацию файлов на сайте с расширение «.aspx»:
Disallow: *.aspx |
Во избежания возникновения неприятных проблем с зеркалами сайта (Домены с www и без www — история появления, использование 301 редиректа для их склеивания) , рекомендуется добавлять в файлrobots.txt директиву Host , которая указывает роботу Яндекса на главное зеркало вашего сайта (Директива Host, позволяющая задать главное зеркало сайта для Яндекса). По правилам написания robots.txt в записи для User-agent должна быть хотя бы одна директива Disallow (обычно ставят пустую, ничего не запрещающую):
User-agent: Yandex Host: www.site.ru |
Robots и Robots.txt — запрет индексации поисковыми системами дубликатов на сайте
Существует еще один способнастроить индексацию отдельных страниц сайта для Яндекса и Гугле. Для этого внутри тега «HEAD» нужной страницы, прописывается МЕТА-тег Robots и так повторяется для всех страниц, к которым нужно применить то или иное правило индексации (запрет или разрешение). Пример применения мета-тега:
В этом случае роботы всех поисковых систем должны будут забыть об индексации этой страницы (об это говорит noindex в мета-теге) и анализе размещенных на ней ссылок (об этом говорит nofollow) .
Существуют только две парыдиректив мета тега Robots : index и follow:
- Index — указывают, может ли робот проводить индексацию данной страницы
- Follow — может ли он следовать по ссылкам со страницы
Значения по умолчанию – «index» и «follow». Есть также укороченный вариант написания с использованием «all» и «none», которые обозначают активность всех директив или, соответственно, наоборот: all=index,follow и none=noindex,nofollow .
Для блога на WordPress вы сможете настроить мета-тег Robots, например, с помощью плагинаAll in One SEO Pack . Ну все, с теорией покончено и пора переходить к практике, а именно, к составлению оптимальных файлов robots.txt для Joomla, SMF и WordPress.
Как известно, у проектов, созданных на основе какого-либо движка (Joomla, WordPress, SMF и др), имеется множество вспомогательных файлов не несущих никакой информативной нагрузки.
Если не запретить индексацию всего этого мусора вrobots.txt , то время, отведенное поисковыми системами Яндекс и Гугл на индексацию вашего сайта, будет тратиться на перебор поисковыми роботами файлов движка на предмет поиска в них информационной составляющей, т.е. контента, который, кстати, в большинстве CMS хранится в базе данных, к которой поисковым роботам никак не добраться (вы можете работать с базами черезPhpMyAdmin). В этом случае, времени на полноценнуюиндексацию сайта у роботов Яндекса и Гугла может не остаться.
Кроме того, следует стремиться к уникальности контента на своем проекте и не следует допускать дублирования контента (информационного содержимого) вашего сайта при индексировании. Дублирование может возникнуть в том случае, если один и тот же материал будет доступен по разным адресам (URL). Поисковые системы Яндекс и Гугл, проводя индексацию сайта, обнаружат дубли и, возможно, примут меры к некоторой пессимизации вашего ресурса при их большом количестве.
Если ваш проект создан на основе какого-либо движка (Joomla, SMF, WordPress), то дублирование контента будет иметь место возможно с высокой вероятностью, а значит нужно с ним бороться, в том числе ис помощью запрета индексации в robots.txt .
Например, в WordPress, страницы с очень похожим содержимым, могут попасть в индекс Яндекса и Гугле если разрешена индексация содержимого рубрик, содержимого архива тегов и содержимого временных архивов. Но если с помощью мета-тега Robots создать запрет на индексацию архива тегов и временного архива (можно теги оставить, а запретить индексацию содержимого рубрик), то дублирования контента не возникнет. Для этой цели в WordPress лучше всего будет воспользоваться возможностямиплагина All in One SEO Pack.
Еще сложнее с дублированием контента обстоит дело в форумном движке SMF. Если не производить тонкую настройку (запрет) индексации сайта в Яндексе и Гугле через robots.txt, то в индекс поисковых систем попадут многократные дубли одних и тех же постов. В Joomla иногда возникает проблема с индексацией и дублированием контента обычных страниц и их копий, предназначенных для печати.
Robots.txt предназначен для задания глобальных правил запрета индексации в целых директориях сайта, либо в файлах и директориях, в названии которых присутствуют заданные символы (по маске). Примеры задания таких запретов индексации вы можете посмотреть в первой статье этой статьи.
Для запрета индексации в Яндексе и Гугле одной единственной страницы, удобно использовать мета-тег Robots, который прописывается в шапке (между тегами HEAD) нужной страницы. Подробно о синтаксисе мета-тега Robots чуть выше по тексту. Для запрета индексации внутри страницы можно использовать тег NOINDEX , но он, правда, поддерживается только поисковой системой Яндекс.
Директива Host в robots.txt для Яндекса
Теперь давайте рассмотрим конкретные примеры robots.txt, предназначенного для разных движков — Joomla, WordPress и SMF. Естественно, что все три файла robots.txt, созданные для разных движков, будут существенно (если не сказать кардинально) отличаться друг от друга. Правда, будет во всех этих robots.txt один общий момент и момент этот связан с поисковой системой Яндекс.
Т.к. в рунете поисковик Яндекс имеет достаточно большой вес, то нужно учитывать все нюансы его работы, то для корректнойиндексации сайта в Яндексе нужна директива Host в robots.txt . Эта директива, в явной форме, укажет Яндексу главное зеркало вашего сайта. Более подробно почитать об этом вы можете здесь:Директива Host, позволяющая задать главное зеркало сайта для Яндекса.
Для указания директивы Host советуют использовать отдельный блог User-agent в файле robots.txt, предназначенный только для Яндекса (User-agent: Yandex). Это связано с тем, что остальные поисковые системы могут не понимать директиву Host и, соответственно, ее включение в директиву User-agent, предназначенную для всех поисковиков (User-agent: *), может привести к негативным последствиям и неправильной индексации вашего сайта.
Как обстоит дело на самом деле — сказать трудно, ибоалгоритмы работы поисковиков — это вещь в себе, поэтому лучше сделать в robots.txt все так, как советуют. Но в этом случае в файле robots.txt вам придется дублировать в директиве User-agent: Yandex все те правила, что вы задали в директиве User-agent: * . Если вы оставите директиву User-agent: Yandex с пустой директивой Disallow: , то таким образом выв robots.txt разрешите Яндексу индексацию всего сайта .
Прежде чем перейти к рассмотрению конкретных вариантов файла robots.txt, хочу вам напомнить, что проверить работу своего файла robots.txt вы можете в Яндекс ВебмастериГугл Вебмастер.
Правильный robots.txt для форума SMF
Allow: /forum/*sitemap Allow: /forum/*arcade Allow: /forum/*rss Disallow: /forum/attachments/ Disallow: /forum/avatars/ Disallow: /forum/Packages/ Disallow: /forum/Smileys/ Disallow: /forum/Sources/ Disallow: /forum/Themes/ Disallow: /forum/Games/ Disallow: /forum/*.msg Disallow: /forum/*. new Disallow: /forum/*sort Disallow: /forum/*topicseen Disallow: /forum/*wap Disallow: /forum/*imode Disallow: /forum/*action User-agent: Slurp Crawl-delay: 100 |
Обратите внимание, что этот robots.txt приведен для того случая, когда ваш форум SMF установлен в директории forum основного сайта. Если форум не стоит в директории, то просто удалите из всех правил /forum . Авторы данного варианта файла robots.txt для форума на движке SMF говорят, что он даст максимальный эффект для правильной индексации в Яндексе и Гугле, если вы не будете активировать на своем форуме дружественные URL (ЧПУ).
Дружественные URL в SMF можно активировать или дезактивировать в админке форума, пройдя по следующему пути: в левой колонке админки выбираете пункт «Характеристики и настройки», в нижней части открывшегося окна находите пункт "Разрешить дружественные URL ", где можете поставить или снять галочку.
Еще одинправильный файл robots.txt для форума SMF (но, наверное, еще не окончательно оттестированный):
Allow: /forum/*sitemap Allow: /forum/*arcade # если не стоит мод игр, удалить без пропуска строки Allow: /forum/*rss Allow: /forum/*type=rss Disallow: /forum/attachments/ Disallow: /forum/avatars/ Disallow: /forum/Packages/ Disallow: /forum/Smileys/ Disallow: /forum/Sources/ Disallow: /forum/Themes/ Disallow: /forum/Games/ Disallow: /forum/*.msg Disallow: /forum/*. new Disallow: /forum/*sort Disallow: /forum/*topicseen Disallow: /forum/*wap Disallow: /forum/*imode Disallow: /forum/*action Disallow: /forum/*prev_next Disallow: /forum/*all Disallow: /forum/*go.php # либо тот редирект что стоит у вас Host: www.мой сайт.ru # указать ваше главное зеркало User-agent: Slurp Crawl-delay: 100 |
Как вы можете видеть в этом robots.txt, директива Host , предназначенная только для Яндекса, включена в директиву User-agent для всех поисковиков. Я бы, наверное, все-таки добавил отдельную директиву User-agent в robots.txt только для Яндекса, с повтором всех правил. Но решайте сами.
User-agent: Slurp Crawl-delay: 100 |
связано с тем, что поисковая система Yahoo (Slurp — это имя его поискового бота) производит индексацию сайта в много потоков, что может негативно сказаться на его производительности. В этом правиле robots.txt, директива Crawl-delay, позволяет задать поисковому роботу Yahoo минимальный период времени (в секундах) между концом закачки одной страницы и началом закачки следующей. Это позволит снять нагрузку на серверпри индексации сайта поисковой системой Yahoo .
Для запрета индексации в Яндексе и Гугле версий для печати страниц форума SMF рекомендуют проделать, описанные ниже операции (для их осуществления понадобится открыть некоторые файлы SMF на редактирование с помощью программы FileZilla). В файле Sources/Printpage.php находите (например, с помощью встроенного поиска вNotepad++) строку:
В файле Themes/название_вашей_темы_оформления/Printpage.template.php находите строку:
Если вы так же хотите, чтобы в версии для печати была ссылка для перехода на полную версию форума (в случае, если часть страниц для печати уже прошла индексацию в Яндексе и Гугле), то в том же файле Printpage.template.php вы находите строку с открывающим тегом HEAD:
Получить больше информации по этому варианту файлаrobots.txt для форума SMF вы можете, почитавэту ветку русскоязычного форума поддержки SMF.
Правильный robots.txt для сайта на Joomla
Robots.txt – это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нем, какие страницы и данные закрыть от индексации от поисковых систем. Файл содержит директивы, описывающие доступ к разделам сайта (так называемый стандарт исключений для роботов). Например, с его помощью можно установить различные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров. Очень важно настроить его правильно.
Нужен ли robots.txt?
С помощью robots.txt можно:
- запретить индексирование похожих и ненужных страниц, чтобы не тратить краулинговый лимит (количество URL, которое может обойти поисковый робот за один обход). Т.е. робот сможет проиндексировать больше важных страниц.
- скрыть изображения из результатов поиска.
- закрыть от индексации неважные скрипты, файлы стилей и другие некритичные ресурсы страниц.
Если это помешает сканеру Google или Яндекса анализировать страницы, не блокируйте файлы.
Где лежит файл Robots.txt?
Если вы хотите просто посмотреть, что находится в файле robots.txt, то просто введите в адресной строке браузера: site.ru/robots.txt.
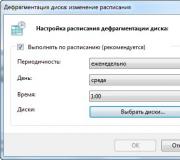
Физически файл robots.txt находится в корневой папке сайта на хостинге. У меня хостинг beget.ru , поэтому покажу расположения файла robots.txt на этом хостинге.

Как создать правильный robots.txt
Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует или разрешает индексирование пути на сайте.
- В текстовом редакторе создайте файл с именем robots.txt и заполните его в соответствии с представленными ниже правилами.
- Файл robots.txt должен представлять собой текстовый файл в кодировке ASCII или UTF-8. Символы в других кодировках недопустимы.
- На сайте должен быть только один такой файл.
- Файл robots.txt нужно разместить в корневом каталоге сайта. Например, чтобы контролировать индексацию всех страниц сайта http://www.example.com/ , файл robots.txt следует разместить по адресу http://www.example.com/robots.txt . Он не должен находиться в подкаталоге (например, по адресу http://example.com/pages/robots.txt ). В случае затруднений с доступом к корневому каталогу обратитесь к хостинг-провайдеру. Если у вас нет доступа к корневому каталогу сайта, используйте альтернативный метод блокировки, например метатеги.
- Файл robots.txt можно добавлять по адресам с субдоменами (например, http://website .example.com/robots.txt) или нестандартными портами (например, http://example.com:8181 /robots.txt).
- Проверьте файл в сервисе Яндекс.Вебмастер и Google Search Console.
- Загрузите файл в корневую директорию вашего сайта.
Вот пример файла robots.txt с двумя правилами. Ниже есть его объяснение.
User-agent: Googlebot Disallow: /nogooglebot/ User-agent: * Allow: / Sitemap: http://www.example.com/sitemap.xml
Объяснение
- Агент пользователя с названием Googlebot не должен индексировать каталог http://example.com/nogooglebot/ и его подкаталоги.
- У всех остальных агентов пользователя есть доступ ко всему сайту (можно опустить, результат будет тем же, так как полный доступ предоставляется по умолчанию).
- Файл Sitemap этого сайта находится по адресу http://www.example.com/sitemap.xml.
Директивы Disallow и Allow
Чтобы запретить индексирование и доступ робота к сайту или некоторым его разделам, используйте директиву Disallow.
User-agent: Yandex Disallow: / # блокирует доступ ко всему сайту User-agent: Yandex Disallow: /cgi-bin # блокирует доступ к страницам, # начинающимся с "/cgi-bin"
В соответствии со стандартом перед каждой директивой User-agent рекомендуется вставлять пустой перевод строки.
Символ # предназначен для описания комментариев. Все, что находится после этого символа и до первого перевода строки не учитывается.
Чтобы разрешить доступ робота к сайту или некоторым его разделам, используйте директиву Allow
User-agent: Yandex Allow: /cgi-bin Disallow: / # запрещает скачивать все, кроме страниц # начинающихся с "/cgi-bin"
Недопустимо наличие пустых переводов строки между директивами User-agent, Disallow и Allow.
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
# Исходный robots.txt: User-agent: Yandex Allow: /catalog Disallow: / # Сортированный robots.txt: User-agent: Yandex Disallow: / Allow: /catalog # разрешает скачивать только страницы, # начинающиеся с "/catalog" # Исходный robots.txt: User-agent: Yandex Allow: / Allow: /catalog/auto Disallow: /catalog # Сортированный robots.txt: User-agent: Yandex Allow: / Disallow: /catalog Allow: /catalog/auto # запрещает скачивать страницы, начинающиеся с "/catalog", # но разрешает скачивать страницы, начинающиеся с "/catalog/auto".
При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow.
Использование спецсимволов * и $
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
User-agent: Yandex Disallow: /cgi-bin/*.aspx # запрещает "/cgi-bin/example.aspx" # и "/cgi-bin/private/test.aspx" Disallow: /*private # запрещает не только "/private", # но и "/cgi-bin/private"
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
Www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123 www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
Www.example.com/some_dir/get_book.pl?book_id=123
Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&..&pn]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.php
Регистр учитывается. Действует ограничение на длину правила - 500 символов. Например:
Clean-param: abc /forum/showthread.php Clean-param: sid&sort /forum/*.php Clean-param: someTrash&otherTrash
Директива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads Sitemap: http://site.ru/sitemap.xml # адрес карты сайта User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогичноRobots.txt пример для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Robots.txt пример для Bitrix
User-agent: *
Disallow: /*index.php$
Disallow: /bitrix/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*?action=
Disallow: /*action=ADD_TO_COMPARE_LIST
Disallow: /*action=DELETE_FROM_COMPARE_LIST
Disallow: /*action=ADD2BASKET
Disallow: /*action=BUY
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*BACKURL=*
Disallow: /*back_url=*
Disallow: /*BACK_URL=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*COURSE_ID=
Disallow: /*?COURSE_ID=
Disallow: /*?PAGEN
Disallow: /*PAGEN_1=
Disallow: /*PAGEN_2=
Disallow: /*PAGEN_3=
Disallow: /*PAGEN_4=
Disallow: /*PAGEN_5=
Disallow: /*PAGEN_6=
Disallow: /*PAGEN_7=
Disallow: /*PAGE_NAME=search
Disallow: /*PAGE_NAME=user_post
Disallow: /*PAGE_NAME=detail_slide_show
Disallow: /*SHOWALL
Disallow: /*show_all=
Sitemap: http://путь к вашей карте XML формата
Robots.txt пример для MODx
User-agent: *
Disallow: /assets/cache/
Disallow: /assets/docs/
Disallow: /assets/export/
Disallow: /assets/import/
Disallow: /assets/modules/
Disallow: /assets/plugins/
Disallow: /assets/snippets/
Disallow: /install/
Disallow: /manager/
Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *
Disallow: /database/
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /sites/
Disallow: /themes/
Disallow: /scripts/
Disallow: /updates/
Disallow: /profiles/
Disallow: /profile
Disallow: /profile/*
Disallow: /xmlrpc.php
Disallow: /cron.php
Disallow: /update.php
Disallow: /install.php
Disallow: /index.php
Disallow: /admin/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /search/
Disallow: /user/register/
Disallow: /user/password/
Disallow: *register*
Disallow: *login*
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Allow: /*?page=
Disallow: /*?
Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
Сделать это можно при помощи специального инструмента от Яндекс - Яндекс.Вебмастер , еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots.txt или по ссылке http://webmaster.yandex.ru/robots.xml
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла robots.txt . Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования.
- Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота .
- Нажмите кнопку ПРОВЕРИТЬ .
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН . В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru .С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru .В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots.txt и загрузить в корневой каталог вашего сайта.
Передо мной возникла задача исключить из индексирования поисковыми системами страницы, содержащие определённую строку запроса (уникальные для пользователя отчёты, каждый из которых имеет свой адрес). Я решил эту задачу для себя, а также решил полностью разобраться с вопросами разрешения и запрещения индексирования сайта. Этому посвящён данный материал. В нём рассказывается не только о продвинутых случаях использования robots.txt, но также и других, менее известных способах контроля индексации сайта.
В Интернете много примеров, как исключить определённые папки из индексации поисковыми системами. Но может возникнуть ситуация, когда нужно исключить страницы, причём не все, а содержащие только указанные параметры.
Пример страницы с параметрами: сайт.ru/?act=report&id=7a98c5
Здесь act - это имя переменной, значение которой report , и id - это тоже переменная со значением 7a98c5 . Т.е. строка запроса (параметры) идут после знака вопроса.
Закрыть страницы с параметрами от индексирования можно несколькими способами:
- с помощью файла robots.txt
- с помощью правил в файле.htaccess
- с помощью метатега robots
Контроль индексации в файле robots.txt
Файл robots.txt
Файл robots.txt - это простой текстовый файл, который размещается в корневой директории (папке) сайта, и содержащий одну или более записей. Типичный пример содержимого файла:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/
В этом файле из индексации исключены три директории.
Помните, что строку с "Disallow " нужно писать отдельно для каждого URL префикса, который вы хотите исключить. То есть вы не можете написать "Disallow: /cgi-bin/ /tmp/ " в одну строку. Также помните о специальном значении пустых строк - они разделяют блоки записей.
Регулярные выражения не поддерживаются ни в строке User-agent , ни в Disallow .
Файл robots.txt должен размещаться в корневой папке вашего сайта. Его синтаксис следующий:
User-agent: * Disallow: /папка или страница, запрещённая для индексации Disallow: /другая папка
В качестве значения User-agent указана * (звёздочка) - это соответствует любому значению, т.е. правила предназначены для всех поисковых машин. Вместо звёздочки можно указать имя определённой поисковой машины, для которой предназначено правило.
Можно указать более чем одну директиву Disallow .
В файле robots.txt можно использовать подстановочный символы:
- * обозначает 0 или более экземпляров любого действительного символа. Т.е. это любая строка, в том числе и пустая.
- $ обозначает конец URL.
Другие символы, в том числе &, ?, = и т.д. понимаются буквально.
Запрет индексации страницы с определёнными параметрами с помощью robots.txt
Итак, я хочу заблокировать адреса вида (вместо ЗНАЧЕНИЕ может быть любая строка): сайт.ru/?act=report&id=ЗНАЧЕНИЕ
Для этого подойдёт правило:
User-agent: * Disallow: /*?*act=report&id=*
В нём / (слеш) означает корневую папку сайта, затем следует * (звёздочка), она означает «что угодно». Т.е. это может быть любой относительный адрес, например:
- /page.php
- /order/new/id
Затем следует ? (знак вопроса), который трактуется буквально, т.е. как знак вопроса. Следовательно далее идёт строка запроса.
Вторая * означает, что в строке запроса может быть что-угодно.
Затем идёт последовательность символов act=report&id=* , в ней act=report&id= трактуется буквально, как есть, а последняя звёздочка вновь означает любую строку.
Запрет индексации поисковыми системами, но разрешение для сканеров рекламных сетей
Если вы закрыли сайт от индексирования для поисковых систем, либо закрыли определённые его разделы, то на них не будет показываться реклама AdSense! Размещение рекламы на страницах, закрытых от индексации, может считаться нарушением и в других партнёрских сетях.
Чтобы это исправить, добавьте в самое начало файла robots.txt следующие строки:
User-agent: Mediapartners-Google Disallow: User-agent: AdsBot-Google* Disallow: User-Agent: YandexDirect Disallow:
Этими строками мы разрешаем ботам Mediapartners-Google , AdsBot-Google* и YandexDirect индексировать сайт.
Т.е. файл robots.txt для моего случая выглядит так:
User-agent: Mediapartners-Google Disallow: User-agent: AdsBot-Google* Disallow: User-Agent: YandexDirect Disallow: User-agent: * Disallow: /*?*act=report&id=*
Запрет индексации всех страниц со строкой запроса
Это можно сделать следующим образом:
User-agent: * Disallow: /*?*
Данный пример блокирует все страницы, содержащие в URL ? (знак вопроса).
Помните: знак вопроса, стоящий сразу после имени домена, например, site.ru/? равнозначен индексной странице, поэтому будьте осторожны с данным правилом.
Запрет индексации страниц с определённым параметром, передающимся методом GET
К примеру, нужно заблокировать URL, содержащие в строке запроса параметр order , для этого подойдёт следующее правило:
User-agent: * Disallow: /*?*order=
Запрет индексации страниц с любым из нескольких параметров
Предположим, нам нужно запретить индексировать страницы, содержащие в строке запроса или параметр dir , или параметр order , или параметр p . Для этого перечислите каждый из параметров для блокировки в отдельных правилах примерно следующим образом:
User-agent: * Disallow: /*?*dir= Disallow: /*?*order= Disallow: /*?*p=
Как запретить поисковым системам индексировать страницы, в URL которых несколько определённых параметров
К примеру, нужно исключить из индексации страницы, содержание в строке запроса параметр dir , параметр order и параметр p . К примеру, страница с таким URL должна быть исключена из индексации: mydomain.com/new-printers?dir=asc&order=price&p=3
Этого можно добиться используя директиву:
User-agent: * Disallow: /*?dir=*&order=*&p=*
Вместо значений параметров, которые могут постоянно меняться, используйте звёздочки. Если параметр всегда имеет одно значение, то используйте его буквальное написание.
Как закрыть сайт от индексации
Чтобы запретить всем роботам индексировать весь сайт:
User-agent: * Disallow: /
Разрешение всем роботам полный доступ
Чтобы предоставить всем роботам полный доступ для индексации сайта:
User-agent: * Disallow:
Либо просто создайте пустой файл /robots.txt, либо вообще не используйте его - по умолчанию, всё, что не запрещено для индексации, считается открытым. Поэтому пустой файл, либо его отсутствие - означают разрешение на полное индексирование.
Запрет всем поисковым системам индексировать часть сайта
Чтобы закрыть некоторые разделы сайта от всех роботов, используйте директивы следующего вида, в которых замените значения на свои:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /junk/
Блокировка отдельных роботов
Для закрытия доступа отдельным роботам и поисковым системам, используйте имя робота в строке User-agent . В данном примере закрыт доступ для BadBot :
User-agent: BadBot Disallow: /
Помните: многие роботы игнорируют файл robots.txt, поэтому это не является надёжным средством закрыть сайт или его часть от индексирования.
Разрешить индексировать сайт одной поисковой системой
Допустим, мы хотим разрешить индексировать сайт только Google, а другим поисковым системам закрыть доступ, тогда сделайте так:
User-agent: Google Disallow: User-agent: * Disallow: /
Первые две строки дают разрешение роботу Google на индексацию сайта, а последние две строки запрещают это всем остальным роботам.
Запрет на индексацию всех файлов, кроме одного
Директива Allow определяет пути, которые должны быть доступны указанным поисковым роботам. Если путь не указан, она игнорируется.
Использование:
Allow: [путь]
Важно : Allow должна следовать до Disallow .
Примечание : Allow не является частью стандарта, но многие популярные поисковые системы её поддерживают.
В качестве альтернативы, с помощью Disallow вы можете запретить доступ ко всем папкам, кроме одного файла или одной папки.
Как проверить работу robots.txt
В Яндекс.Вебмастер есть инструмент для проверки конкретных адресов на разрешение или запрет их индексации в соответствии с файлом robots.txt вашего файла.
Для этого перейдите во вкладку Инструменты , выберите Анализ robots.txt . Этот файл должен загрузиться автоматически, если там старая версия, то нажмите кнопку Проверить :
Затем в поле Разрешены ли URL? введите адреса, которые вы хотите проверить. Можно за один раз вводить много адресов, каждый из них должен размещаться на новой строчке. Когда всё готово, нажмите кнопку Проверить .
В столбце Результат если URL адрес закрыт для индексации поисковыми роботами, он будет помечен красным светом, если открыт - то зелёным.

В Search Console имеется аналогичный инструмент. Он находится во вкладке Сканирование . Называется Инструмент проверки файла robots.txt .
Если вы обновили файл robots.txt, то нажмите на кнопку Отправить , а затем в открывшемся окно снова на кнопку Отправить :

После этого перезагрузите страницу (клавиша F5):

Введите адрес для проверки, выберите бота и нажмите кнопку Проверить :
Запрет индексации страницы с помощью мета тега robots
Если вы хотите закрыть страницу от индексации, то в теге … пропишите:
Например, запрет для индексации всех файлов с расширением.PDF:
Запрет для индексации всех файлов изображений (.png, .jpeg, .jpg, .gif):
Блокировка доступа поисковым системам с помощью mod_rewrite
На самом деле, всё, что было описано выше, НЕ ГАРАНТИРУЕТ, что поисковые системы и запрещённые роботы не будут заходить и индексировать ваш сайт. Есть роботы, которые «уважают» файл robots.txt, а есть те, которые его просто игнорируют.
С помощью mod_rewrite можно закрыть доступ для определённых ботов
RewriteEngine On RewriteCond %{HTTP_USER_AGENT} Google RewriteCond %{HTTP_USER_AGENT} Yandex RewriteRule ^ - [F]
Приведённые директивы заблокируют доступ роботам Google и Yandex для всего сайта.
report/
RewriteEngine On RewriteCond %{HTTP_USER_AGENT} Google RewriteCond %{HTTP_USER_AGENT} Yandex RewriteRule ^report/ - [F]
Если вам интересна блокировка доступа для поисковых систем к отдельным страницам и разделам сайта с помощью mod_rewrite, то пишите в комментариях и задавайте ваши вопросы - я подготовлю больше примеров.
13 observations on “Как исключить из индексации страницы с определёнными параметрами в URL и другие техники контроля индексации сайта поисковыми системами ”
- Тарас
самое близкое по значению, но тут папка
Если, допустим, нужно закрыть для индексирования только одну папку report/ , то следующие директивы полностью закроют доступ к этой папке (будет выдаваться код ответа 403 Доступ Запрещён) для сканеров Google и Yandex.
Цель этого руководства – помочь веб-мастерам и администраторам в использовании robots.txt.
Введение
Стандарт исключений для роботов по сути своей очень прост. Вкратце, это работает следующим образом:
Когда робот, соблюдающий стандарт заходит на сайт, он прежде всего запрашивает файл с названием «/robots.txt». Если такой файл найден, Робот ищет в нем инструкции, запрещающие индексировать некоторые части сайта.
Где размещать файл robots.txt
Робот просто запрашивает на вашем сайте URL «/robots.txt», сайт в данном случае – это определенный хост на определенном порту.
| URL Сайта | URL файла robots.txt |
| http://www.w3.org/ | http://www.w3.org/robots.txt |
| http://www.w3.org:80/ | http://www.w3.org:80/robots.txt |
| http://www.w3.org:1234/ | http://www.w3.org:1234/robots.txt |
| http://w3.org/ | http://w3.org/robots.txt |
На сайте может быть только один файл «/robots.txt». Например, не следует помещать файл robots.txt в пользовательские поддиректории – все равно роботы не будут их там искать. Если вы хотите иметь возможность создавать файлы robots.txt в поддиректориях, то вам нужен способ программно собирать их в один файл robots.txt, расположенный в корне сайта. Вместо этого можно использовать .
Не забывайте, что URL-ы чувствительны к регистру, и название файла «/robots.txt» должно быть написано полностью в нижнем регистре.
| Неправильное расположение robots.txt | |
| http://www.w3.org/admin/robots.txt | |
| http://www.w3.org/~timbl/robots.txt | Файл находится не в корне сайта |
| ftp://ftp.w3.com/robots.txt | Роботы не индексируют ftp |
| http://www.w3.org/Robots.txt | Название файла не в нижнем регистре |
Как видите, файл robots.txt нужно класть исключительно в корень сайта.
Что писать в файл robots.txt
В файл robots.txt обычно пишут нечто вроде:
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
В этом примере запрещена индексация трех директорий.
Затметьте, что каждая директория указана на отдельной строке – нельзя написать «Disallow: /cgi-bin/ /tmp/». Нельзя также разбивать одну инструкцию Disallow или User-agent на несколько строк, т.к. перенос строки используется для отделения инструкций друг от друга.
Регулярные выражения и символы подстановки так же нельзя использовать. «Звездочка» (*) в инструкции User-agent означает «любой робот». Инструкции вида «Disallow: *.gif» или «User-agent: Ya*» не поддерживаются.
Конкретные инструкции в robots.txt зависят от вашего сайта и того, что вы захотите закрыть от индексации. Вот несколько примеров:
Запретить весь сайт для индексации всеми роботами
User-agent: *
Disallow: /
Разрешить всем роботам индексировать весь сайт
User-agent: *
Disallow:
Или можете просто создать пустой файл «/robots.txt».
Закрыть от индексации только несколько каталогов
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /private/
Запретить индексацию сайта только для одного робота
User-agent: BadBot
Disallow: /
Разрешить индексацию сайта одному роботу и запретить всем остальным
User-agent: Yandex
Disallow:
User-agent: *
Disallow: /
Запретить к индексации все файлы кроме одного
Это довольно непросто, т.к. не существует инструкции “Allow”. Вместо этого можно переместить все файлы кроме того, который вы хотите разрешить к индексации в поддиректорию и запретить ее индексацию:
User-agent: *
Disallow: /docs/
Либо вы можете запретить все запрещенные к индексации файлы:
User-agent: *
Disallow: /private.html
Disallow: /foo.html
Disallow: /bar.html
От автора: У вас на сайте есть страницы, которые вы бы не хотели показывать поисковым системам? Из этой статье вы узнаете подробно о том, как запретить индексацию страницы в robots.txt, правильно ли это и как вообще правильно закрывать доступ к страницам.
Итак, вам нужно не допустить индексацию каких-то определенных страниц. Проще всего это будет сделать в самом файле robots.txt, добавив в него необходимые строчки. Хочу отметить, что адреса папок мы прописывали относительно, url-адреса конкретных страниц указывать таким же образом, а можно прописать абсолютный путь.
Допустим, на моем блоге есть пару страниц: контакты, обо мне и мои услуги. Я бы не хотел, чтобы они индексировались. Соответственно, пишем:
User-agent: * Disallow: /kontakty/ Disallow: /about/ Disallow: /uslugi/
Другой вариант
Отлично, но это не единственный способ закрыть роботу доступ к определенным страничкам. Второй – это разместить в html-коде специальный мета-тег. Естественно, разместить только в тех записях, которые нужно закрыть. Выглядит он так:
< meta name = "robots" content = "noindex,nofollow" > |
Тег должен быть помещен в контейнер head в html-документе для корректной работы. Как видите, у него два параметры. Name указывается как робот и определяет, что эти указания предназначены для поисковых роботов.
Параметр же content обязательно должен иметь два значения, которые вписываются через запятую. Первое – запрет или разрешение на индексацию текстовой информации на странице, второе – указание насчет того, индексировать ли ссылки на странице.
Таким образом, если вы хотите, чтобы странице вообще не индексировалась, укажите значения noindex, nofollow, то есть не индексировать текст и запретить переход по ссылкам, если они имеются. Есть такое правило, что если текста на странице нет, то она проиндексирована не будет. То есть если весь текст закрыт в noindex, то индексироваться нечему, поэтому ничего и не будет попадать в индекс.
Кроме этого есть такие значения:
noindex, follow – запрет на индексацию текста, но разрешение на переход по ссылкам;
index, nofollow – можно использовать, когда контент должен быть взят в индекс, но все ссылки в нем должны быть закрыты.
index, follow – значение по умолчанию. Все разрешается.