Vkládání objektů - výuka informatiky. Extrahujte jedinečný seznam z jednoho sloupce pomocí možnosti Rozšířený filtr. Součet, pokud buňky nejsou sekvenční
Testové úlohy na téma: „Tabulky Vynikat ».
1. Tabulka je:
a) aplikační program pro ukládání a zpracování dat strukturovaných ve formě tabulky;
b) aplikační program pro zpracování kódových tabulek;
c) zařízení osobní počítač, řízení svých zdrojů v procesu zpracování dat v tabulkové formě;
d) systémový program, který spravuje prostředky osobního počítače při práci s tabulkami.
2. Základní rozdíl mezi tabulkovým procesorem a běžným procesorem je:
a) schopnost zpracovávat data strukturovaná ve formě tabulky;
b) schopnost automaticky přepočítat data určená vzorci při změně původních dat;
c) schopnost vizuálně znázornit souvislosti mezi zpracovávanými daty;
d) schopnost zpracovávat data prezentovaná v řetězcích různé typy.
3. Řádky tabulky:
a) jsou pojmenovány uživatelem libovolným způsobem;
b) jsou označeny písmeny ruské abecedy A...Z;
c) jsou označeny písmeny latinské abecedy;
d) jsou očíslovány.
4. Adresa buňky v Excelu se skládá z:
a) název souboru;
b) daný soubor znaků;
c) název sloupce a číslo řádku, na jehož průsečíku se buňka nachází;
d) číslo řádku a název sloupce, na jehož průsečíku se buňka nachází.
5. Pokud v Excelu aktivujete buňku a stisknete klávesu Delete, pak:
a) obsah buňky bude smazán;
b) formát buňky bude vymazán;
c) buňka bude smazána;
d) název buňky bude smazán.
6. Informace v tabulce jsou uvedeny takto:
a) soubory; b) záznamy; c) text, čísla, vzorce.
7. Rychlý převod dat do tabulkový procesor se děje kvůli...
a) distribuce informací mezi buňkami;
b) přítomnost vzorců spojujících data;
c) rychlý chod procesoru.
8. Aktivní buňka v Excelu je:
a) buňka s adresou A1; b) buňka zvýrazněná rámečkem; c) buňku, do které se zapisují údaje.
9. Rozsah buněk v tabulce je...
a) soubor všech vyplněných buněk tabulky;
b) soubor všech prázdné buňky;
c) sadu buněk tvořících obdélníkovou oblast;
d) soubor buněk tvořících plochu volná forma.
10.Uveďte neplatný vzorec pro buňku F1
a) =A1+B1*D1; b) =A1+B1/F1; c) = Cl.
11. Zadejte neplatný vzorec pro zápis do buňky D1
a) = 2Ai+B2; b) =Ai+B2+C3; c) =Ai-C3; d) všechny vzorce jsou přijatelné.
12. Nemůžete mazat v tabulce.
a) řádek; b) sloupec; c) název buňky; d) obsah buňky.
13. V tabulce je zvýrazněna skupina buněkC 3: F 10. Kolik buněk je v této skupině?
a) 21; b) 24; c) 28; d) 32.
14. Výraz , napsaný v souladu s pravidly přijatými v matematice, v tabulce má tvar:
a)3*(A1+B1)/(5*(2*B1–3*A2));
b)3(A1+B1)/5(2B1–3A2);
c)3* (A1+B1)/ 5* (2* B1–3* A2);
d)3(A1+B1)/(5(2B1–3A2)).
15. Při přesouvání nebo kopírování v tabulce absolutní odkazy:
a) neměnit;
b) jsou transformovány bez ohledu na novou pozici vzorce;
c) jsou transformovány v závislosti na nové pozici vzorce;
d) se transformují v závislosti na délce vzorce.
16 . Buňka tabulky H5 obsahuje vzorec =$B$5*V5. Jaký vzorec se z něj získá při zkopírování do buňky H7:
a)=$B$7*V7; b)=$B$5*V5; c)=$B$5*V7; d) = B$7*V7.
17. V tabulce obsahuje buňka A1 číslo 10, B1 obsahuje vzorec =A1/2 a C1 obsahuje vzorec =SUM(A1:B1). Jaká je hodnota C1:
a)10; b) 15; na 2; d)150.
18. Diagram je:
a) forma grafického znázornění číselných hodnot, která usnadňuje interpretaci číselných údajů;
b) harmonogram;
c) připravený stůl;
19. Sloupcový graf je:
a) diagram, ve kterém jsou jednotlivé hodnoty reprezentovány pruhy o různé délce podél osy X;
b) diagram, jehož jednotlivé hodnoty jsou reprezentovány body v kartézském souřadnicovém systému;
c) diagram, ve kterém jsou jednotlivé hodnoty reprezentovány svislými pruhy různé výšky;
d) diagram prezentovaný ve formě kruhu rozděleného do sektorů, ve kterém je povolena pouze jedna řada dat.
20. Histogram je nejvhodnější pro:
a) k zobrazení distribucí;
b) srovnání různých prvků skupiny;
c) zobrazit dynamiku změn dat;
d) k zobrazení konkrétních poměrů různých charakteristik.
Odpovědi:
Toto je kapitola z knihy: Michael Girvin. Ctrl+Shift+Enter. Zvládnutí maticových vzorců v Excelu.
Tato poznámka je pro ty, kteří se skutečně zajímají o složité maticové vzorce. Pokud potřebujete pouze jednou extrahovat seznam jedinečných hodnot, je mnohem jednodušší použít rozšířený filtr nebo kontingenční tabulku. Hlavní výhody použití vzorců jsou: automatická aktualizace při změně/přidávání zdrojových dat nebo kritérií výběru. Před čtením je vhodné osvěžit si paměť myšlenek obsažených v předchozích materiálech:
- (kapitola 11);
- (kapitola 13);
- (kapitola 15);
- (Kapitola 17).
Rýže. 19.1. Získejte jedinečné záznamy pomocí volby Pokročilý filtr
Stáhněte si poznámku ve formátu nebo formátu, příklady ve formátu
Načtení jedinečného seznamu z jednoho sloupce pomocí volby Pokročilý filtr
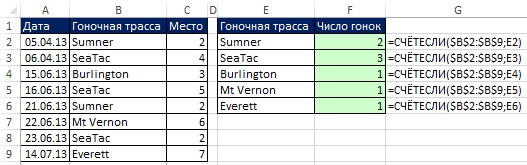
Na Obr. Obrázek 19.1 ukazuje soubor dat (rozsah A1:C9). Vaším cílem je získat seznam unikátních závodních tratí. Protože potřebujete uložit původní data, nemůžete tuto možnost použít Odstraňte duplikáty(Jídelní lístek DATA –> Pracovat s data –> Odstraňte duplikáty). Ale můžete použít Pokročilý filtr. Chcete-li otevřít dialogové okno Pokročilý filtr, projděte nabídku DATA –> Třídění a filtrování –> dodatečně nebo stiskněte a podržte Klávesa Alt a poté stiskněte Y, L (pro Excel 2007 nebo novější).
V dialogovém okně, které se otevře Pokročilý filtr(obr. 19.1) nastavte volbu zkopírujte výsledek na jiné místo, zaškrtněte políčko Pouze jedinečné položky, zadejte oblast, ze které budou extrahovány jedinečné hodnoty ($B$1:$B$9), a první buňku, kam budou umístěna extrahovaná data ($E$1). Na Obr. Obrázek 19.2 ukazuje výsledný jedinečný seznam (rozsah E1:E6). Pokud neuvedete název pole Původní sortiment dialogové okno Pokročilý filtr(místo zadání $B$2:$B$9 na obrázku 19.1) bude Excel považovat první řádek rozsahu za název pole a riskujete, že získáte duplikát. Na Obr. Obrázek 19.3 ukazuje jedno z mnoha možných použití jedinečného seznamu.
![]()
Načtení jedinečného seznamu na základě kritéria pomocí volby Pokročilý filtr
V posledním příkladu jste získali jedinečný seznam z jednoho sloupce. Pokročilý filtr může také načíst jedinečnou sadu záznamů (tj. celé řádky ze zdrojové tabulky) pomocí kritéria. Na Obr. Obrázky 19.4 a 19.5 ukazují situaci, kdy potřebujete extrahovat jedinečné záznamy z rozsahu A1:D10, pro který je název společnosti roven ABC. Později v této kapitole uvidíte, jak tuto práci provést pomocí vzorce. Pokud však nepotřebujete, aby byl proces automatický, můžete použít Pokročilý filtr, což je určitě jednodušší než vzorec.
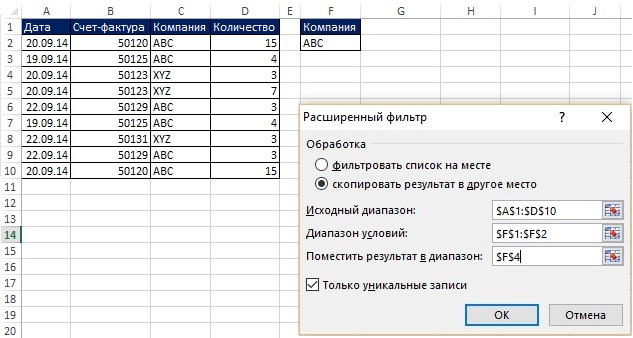
Rýže. 19.4. Potřebujete jedinečné záznamy pro společnost ABC; Chcete-li obrázek zvětšit, klikněte na něj pravým tlačítkem a vyberte Otevřít obrázek na nové kartě
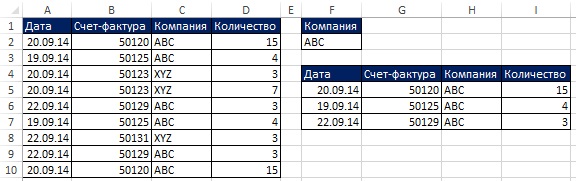
Rýže. 19.5. Používání Pokročilý filtr získat jedinečné záznamy na základě kritérií je mnohem jednodušší než metoda vzorce. Načtené záznamy však nebudou automaticky aktualizovány, pokud se změní kritéria nebo zdrojová data
Načtení jedinečného seznamu z jednoho sloupce pomocí kontingenční tabulky
Pokud již používáte kontingenční tabulky, pak to víte pokaždé, když do oblasti vložíte jakékoli pole Struny nebo Sloupce(obr. 19.6), automaticky obdržíte unikátní seznam. Na Obr. Obrázek 19.6 ukazuje, jak můžete rychle vytvořit jedinečný seznam závodních tratí a poté spočítat počet návštěv každé tratě. Zatímco kontingenční tabulka je užitečná pro načtení jedinečného seznamu z jednoho sloupce, nebudete ji považovat za užitečnou pro načtení jedinečných záznamů na základě kritérií.

Rýže. 19.6. Můžeš použít kontingenční tabulka když potřebujete unikátní seznam a následný výpočet na jeho základě
Extrahování jedinečného seznamu z jednoho sloupce pomocí vzorců a pomocného sloupce
Použití pomocného sloupce usnadňuje získávání jedinečných dat než použití maticových vzorců (obrázek 19.7). Tento příklad používá metody, které jste se naučili v (Použití funkce COUNTIF) a (Použití pomocného sloupce). Pokud nyní změníte zdrojová data v rozsahu B2:B9, vzorce automaticky projeví tyto změny v oblasti D15:D21.
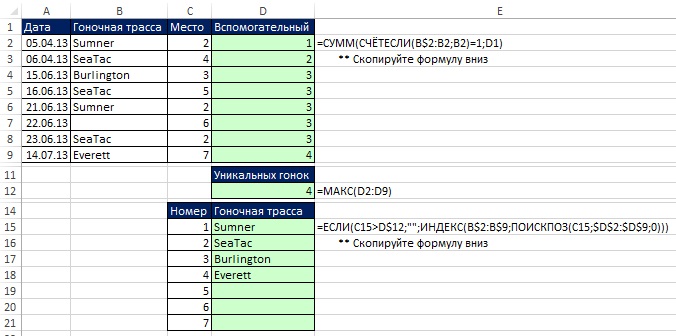
Vzorec pole: Načtení jedinečného seznamu z jednoho sloupce pomocí funkce SMALL
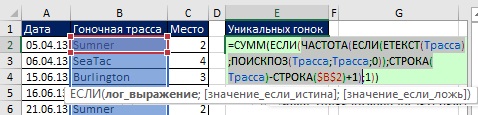
Protože maticové vzorce použité v této části jsou poměrně složité na pochopení, jejich vytvoření je rozděleno do fází: za prvé, fragment, který počítá jedinečné hodnoty (kapitola 17); druhým je extrakce dat na základě kritérií (kapitola 15). Na Obr. Obrázek 19.8 ukazuje vzorec pro výpočet jedinečných hodnot (protože se jedná o maticový vzorec, zadává se stisknutím Ctrl+Shift+Enter). Všimněte si následujících aspektů tohoto vzorce:
- Funkce FREQUENCY vrací pole čísel (obrázek 19.9): pro první výskyt závodní dráhy je vrácen počet jejích výskytů v původních datech; Při každém dalším výskytu závodní dráhy se vrací nula (viz ). Například Sumner se objeví na první a páté pozici pole. Na první pozici vrátí funkce FREQUENCY 2 - celkový počet Léta v rozsahu B2:B9, na páté pozici - 0.
- Funkce FREQUENCY je umístěna v argumentu log_expression Funkce IF, takže funkce IF vrátí hodnotu TRUE pro jakoukoli nenulovou hodnotu a FALSE pro nulovou hodnotu.
- Argument value_if_true Funkce IF obsahuje 1s, takže funkce SUM počítá počet takových 1s.
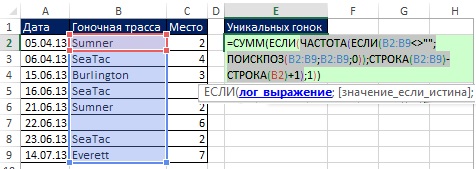
Rýže. 19.8. Funkce FREQUENCY je umístěna v argumentu log_expression IF funkce

Rýže. 19.9. (1) funkce FREQUENCY vrací pole čísel; (2) funkce IF vrací 1 pro nenulová čísla a FALSE pro nuly
Nyní vytvoříme vzorec pro extrakci jedinečného seznamu. Na Obr. Obrázek 19.10 ukazuje pole relativních pozic umístěných v argumentu pole funkce MALÉ.
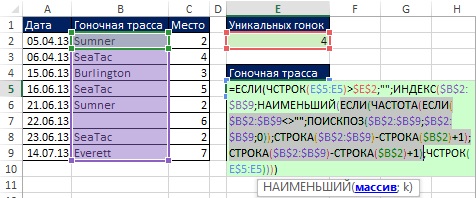
V předchozím příkladu (obr. 19.9) v argumentu value_if_true Funkce IF umístila jedničku, takže funkce IF vrátila jedničky a FALSE. Zde (obr. 19.10) argument value_if_true obsahuje: ROW($B$2:$B$9)-ROW($B$2)+1. Proto funkce IF (v rámci funkce SMALL) vrací relativní číslo pozice v rozsahu s jedinečnou závodní tratí, nebo FALSE pro duplikáty (obrázek 19.11).
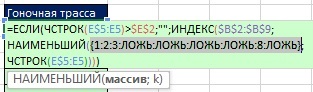
Rýže. 19.11. Funkce IF vrací relativní číslo pozice v rozsahu s jedinečnou závodní tratí, nebo FALSE pro duplikáty
Na Obr. 19.12 ukazují výsledky vzorce. Na Obr. Obrázek 19.13 ukazuje, že jakmile se původní data změnila, vzorce tyto změny okamžitě odrážely. Ale co když přidáte nové položky? Dále uvidíte, jak vytvořit vzorce dynamického rozsahu.
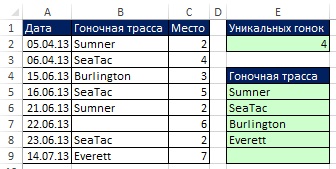
Rýže. 19.13. Pokud se zdrojová data změní, vzorec se okamžitě aktualizuje. Filtr a rozšířený filtr se nemohou automaticky aktualizovat bez napsání kódu VBA
Vzorec pole: Načtení jedinečného seznamu z jednoho sloupce pomocí dynamického rozsahu
Rozšiřme poslední příklad o to, co jste se naučili o vzorcích používajících konkrétní názvy na základě dynamických rozsahů (). Na Obr. 19.14 ukazuje vzorec pro určení jména Trasa. Tento vzorec předpokládá, že nikdy nezadáte položku za řádek 51.
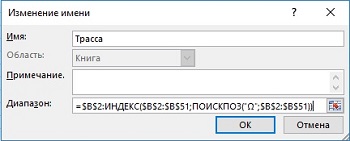
Rýže. 19.14. Definice názvu Trasa na základě vzorce
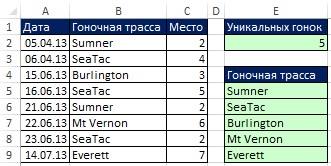
Jakmile definujete název, můžete jej použít v libovolném vzorci. Na Obr. Obrázek 19.15 ukazuje, jak použít název k počítání počtu jedinečných hodnot (srovnej s obrázkem 19.8). A na Obr. Obrázek 19.16 ukazuje vzorec, který extrahuje samotné jedinečné hodnoty ze seznamu závodních tratí. Všimněte si, že místo fragmentu rozsah<>»» (jak tomu bylo na obr. 19.8 a 19.10), je použita funkce ITEXT (jakýkoli text vrátí hodnotu TRUE). Pokud při použití ETEXT zadáte číslo (jako v buňce B11) nebo jakýkoli jiný netext, vzorec bude tuto hodnotu ignorovat. Na Obr. Obrázek 19.17 ukazuje, že vzorec automaticky načte všechny nové názvy stop, ignoruje čísla.
![]()
Rýže. 19.16. Načte jedinečný název trasování na základě dynamického rozsahu
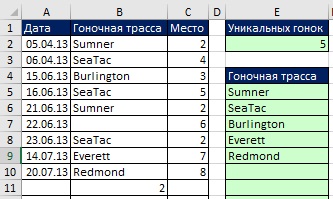
Vytvoření jedinečného vzorce hodnoty pro rozevírací seznam
Na základě právě diskutovaného příkladu definujme druhé jméno - RouteList, také na základě dynamického rozsahu, ale nyní s odkazem na seznam jedinečných tras (rozsah E5:E14, obr. 19.18). Protože rozsah E5:E14 obsahuje pouze text a prázdné hodnoty (testovací řetězce nulové délky - ""), argument vyhledávací_hodnota Funkce MATCH mohou používat zástupné znaky *? (což znamená alespoň jeden znak). A v argumentaci typ_shody Funkce MATCH by měla používat hodnotu -1, která najde poslední textový prvek ve sloupci, který obsahuje alespoň jeden znak. Jak je znázorněno na Obr. 19.18, pak můžete v poli použít konkrétní název Zdroj okno Validace zadaných hodnot(Další informace o vytváření rozevíracího seznamu viz). Rozbalovací seznam se může rozšiřovat a zmenšovat, když se do sloupce B přidávají nebo odebírají nová data.
Pokud se zástupnými znaky má zacházet jako s běžnými znaky
Jak jste se dozvěděli v , někdy by se zástupné znaky měly považovat za znaky. Na Obr. Obrázek 19.18 ukazuje, jak můžete upravit vzorce pro takové případy. Před rozsah argumentů přidáte vlnovku vyhledávací_hodnota MATCH a připojte prázdný řetězec na konec rozsahu v argumentu viewed_array.
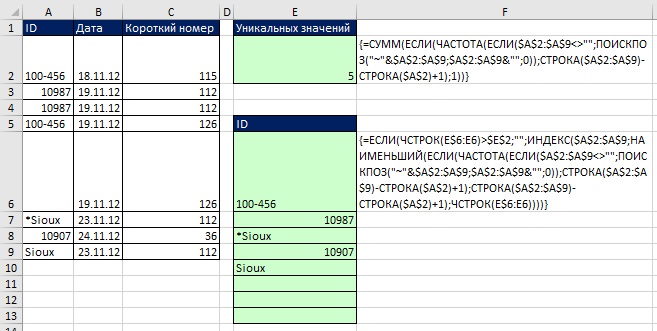
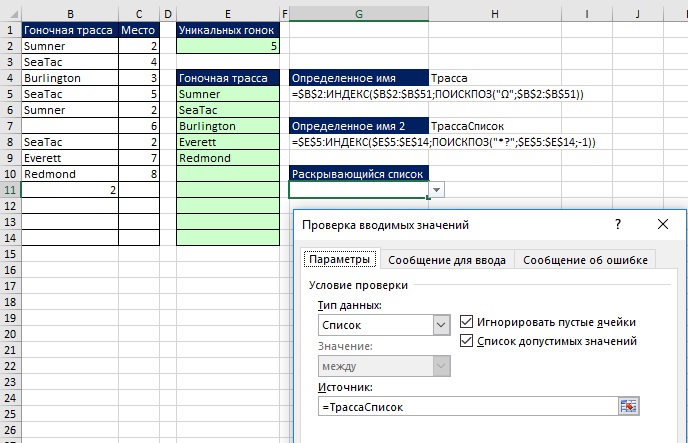
Použijte pomocný sloupec nebo maticový vzorec k načtení jedinečných záznamů na základě kritérií
Na začátku poznámky bylo ukázáno, že pro získávání jedinečných záznamů na základě kritérií, Pokročilý filtr. Pokud však potřebujete okamžitou aktualizaci, můžete použít pomocný sloupec (obrázek 19.20) nebo maticové vzorce (obrázek 19.21).
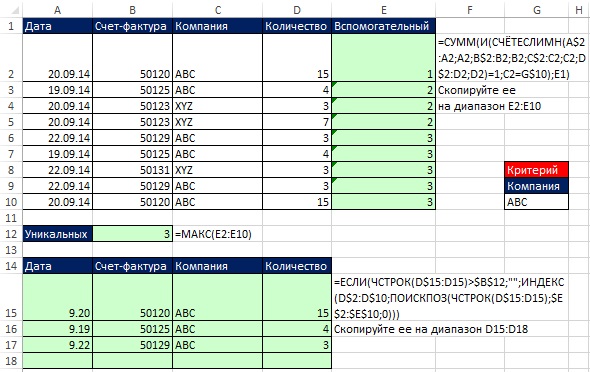

Dynamické vzorce pro extrakci jmen zákazníků a objemu prodeje
Vzorce jsou znázorněny na Obr. 19.22. Pokud například přidáte nový záznam TTNákladní auta na řádek 17 , vzorec SUMIF v buňce F15 automaticky přidá novou hodnotu. Pokud přidáte nového klienta do sloupce B, okamžitě se objeví ve sloupci E a vzorec SUMIF ve sloupci F zobrazí nový součet.
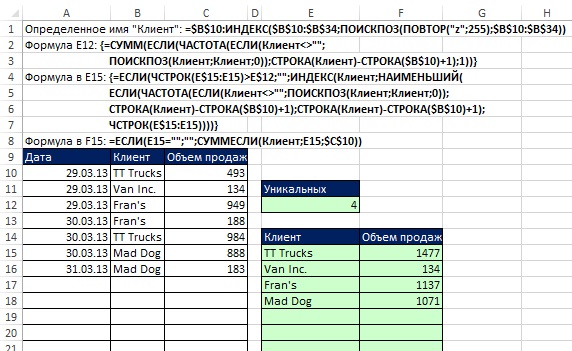
Rýže. 19.22. Použití konkrétního názvu a dvou maticových vzorců k extrakci jedinečných zákazníků a objemu prodeje
Všimněte si, že funkce SUMIF má argument rozsah_součtu obsahuje jednu buňku – $C$10. Odkaz na vzorec SUMSLI k tomuto tématu říká: argument rozsah_součtu nemusí mít stejnou velikost jako argument rozsah. Při určování skutečných buněk, které se mají sečíst, se jako počáteční buňka použije levá horní buňka argumentu rozsah_součtu a pak se sečtou buňky části rozsahu odpovídající velikosti argumentu rozsah. Vzorce zadané do buněk E15 a F15 se zkopírují podél sloupců.
Řazení číselných hodnot
Vzorce pro řazení čísel jsou docela jednoduché, ale vzorce pro řazení smíšených dat jsou šíleně složité. Pokud tedy nevyžadujete okamžitou aktualizaci, je lepší se obejít bez vzorců pomocí možnosti Řazení. Na Obr. Obrázek 19.23 ukazuje dva vzorce řazení.
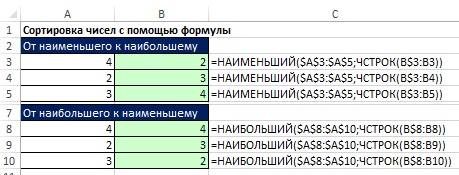
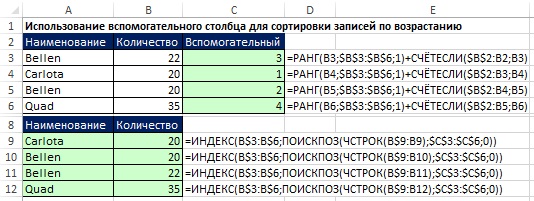
Na Obr. Obrázek 19.24 ukazuje, jak můžete použít pomocný sloupec k řazení čísel. Vzhledem k tomu, že funkce RANK netřídí jako čísla (dává jim stejnou hodnost), je přidána funkce COUNTIF, která je rozlišuje. Všimněte si, že funkce COUNTIF má rozšířený rozsah, který začíná o řádek výše. To je nezbytné, aby první výskyt jakéhokoli čísla nedával příspěvek. Druhé zobrazení čísla zvýší hodnost o jednu. Toto sekvenční číslování určuje pořadí, ve kterém funkce INDEX a MATCH načítají záznamy v rozsahu A8:B12.
Pokud si můžete dovolit vytvořit pomocný sloupec v oblasti extrakce dat (rozsah A10:A14 na obrázku 19.25), je vhodné použít výše popsané řazení čísel na základě funkce SMALL a na základě toho extrahovat názvy pomocí funkce pole.
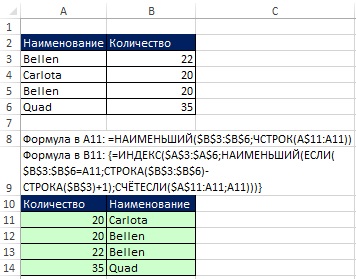
Rýže. 19:25. Pokud nemůžete použít pomocný sloupec, použijte řazení na základě funkce SMALL (v buňce A11) a maticového vzorce (v buňce B11)
V podnikání a sportu často potřebujete extrahovat horní N hodnoty a názvy související s těmito hodnotami. Začněte své řešení pomocí vzorce COUNTIF (buňka A11 na obrázku 19.26), který určí počet záznamů k zobrazení. Všimněte si, že argument kritérium ve funkci COUNTIF v buňce A11 – více nebo stejné hodnotu v buňce D8. To vám umožní zobrazit všechny hraniční hodnoty (v našem příkladu, i když potřebujeme zobrazit Top 3, existují čtyři vhodné hodnoty).
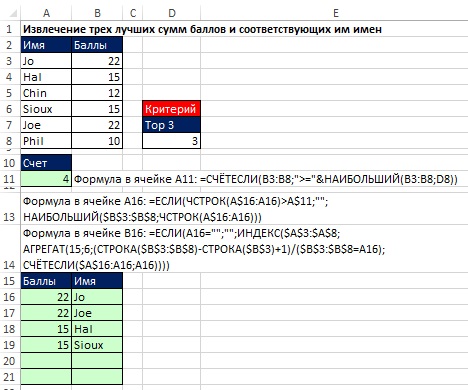
Rýže. 19.26. Extrahování prvních tří celkových skóre a jejich odpovídajících jmen. Když se N změní v buňce D8, oblast A15:B21 bude aktualizována
Třídění textových hodnot
Pokud je použití pomocného sloupku přípustné, není úkol tak obtížný (obr. 19.27). Porovnávací operátory zpracovávají textové znaky na základě číselných kódů ASCII přiřazených znakům. V buňce C3 první funkce COUNTIF vrátí nulu a druhá přidá jedničku. V C4: 2+1, C5: 0+2, C6: 3+1.
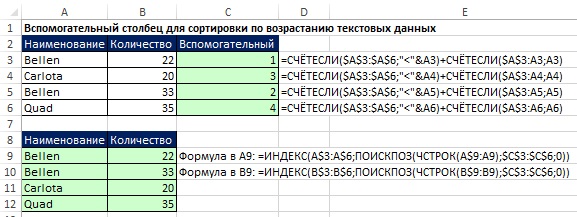
Třídění smíšených dat
Vzorec, který umožňuje extrahovat jedinečné hodnoty ze smíšených dat a poté je třídit, je velmi velký (obrázek 19.28). Při její tvorbě jsme vycházeli z myšlenek, se kterými jsme se setkali dříve v této knize. Začněme se učit vzorec tím, že se podíváme na to, jak funguje standardní funkce řazení v Excelu.
Excel seřadí výsledky v následujícím pořadí: nejprve čísla, potom text (včetně řetězců s nulovou délkou), FALSE, TRUE, chybové hodnoty v pořadí, v jakém se objevují, prázdné buňky. Veškeré řazení probíhá v souladu s kódy ASCII. Existuje 255 ASCII kódů, z nichž každý odpovídá číslu od 1 do 255:
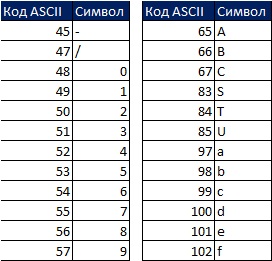
Například číslo 5 odpovídá ASCII kódu 53 a znak S odpovídá ASCII kódu 83. Pokud seřadíte dvě hodnoty, 5 a S, od nejmenší po největší, pak 5 bude vyšší než S, protože 53 je méně než 83.
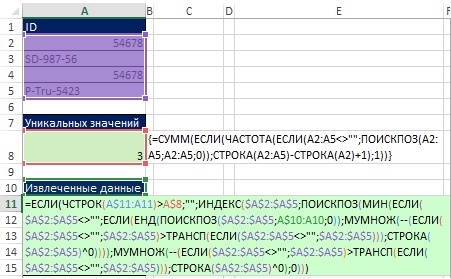
Datový soubor v rozsahu A2:A5 (obr. 29) je převeden do rozsahu E2:E5 v souladu s pravidly třídění. Abyste lépe porozuměli principům řazení, zvažte hodnoty v rozsahu C2:C5. Pokud se například zeptáte na otázku „Kolik lidí mě překonalo?“ na ID v buňce A2 (54678), odpověď bude nula, protože v seřazeném seznamu bude ID 54678 na prvním místě. SD-987-56 bude mít nad sebou tři ID. K získání hodnot v rozsahu C2:C5 potřebujete vzorec.

Pro začátek vyberte rozsah E1:H1 a do řádku vzorců napište =TRANSP(A2:A5) a zadejte vzorec stisknutím Ctrl+Shift+Enter (obr. 19.30). Dále vyberte v řádku vzorců rozsah E2:H5, napište =A2:A5>E1:H1 a zadejte vzorec stisknutím Ctrl+Shift+Enter (obr. 19.31). Na Obr. Obrázek 19.32 ukazuje výsledek, což je obdélníkové pole hodnot TRUE a FALSE, které odpovídají každé buňce ve výsledném poli, jako odpověď na otázku „Je záhlaví řádku větší než záhlaví sloupce?
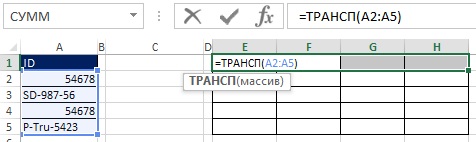
Rýže. 19:30. Vyberte rozsah E1:H1 a zadejte maticové vzorce

Rýže. 19:31. V rozsahu E2:H5 zadejte maticový vzorec =A2:A5>E1:H1
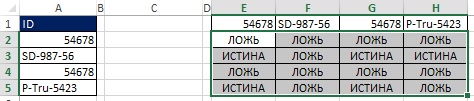
Rýže. 19:32. Každá buňka v rozsahu E2:H5 obsahuje odpověď na otázku „Je záhlaví řádku větší než záhlaví sloupce?“
Například v buňce E3 je otázka: SD-987-56 > 54678. Protože 54678 je menší než SD-987-56, odpověď je PRAVDA. Všimněte si, že rozsah E3:H3 obsahuje tři hodnoty TRUE a jednu hodnotu FALSE. Při pohledu zpět na Obr. 19.29, můžete vidět, že je to číslo tři, které je v buňce C3.
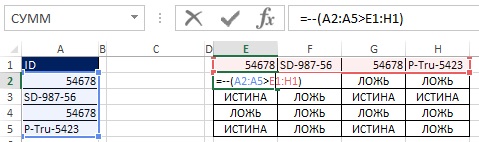
Jak je znázorněno na obrázcích 19.33 a 19.34, hodnoty TRUE a FALSE můžete převést na jedničky a nuly přidáním dvojité negace do maticového vzorce. Protože původní pole (E2:H5) je 4x4 a chcete, aby výsledkem bylo pole 4x1, použijte funkci MULTIPLE (viz obrázek 19.35 a ). Funkce MULTIPLE je funkce pole, zadejte ji tedy stisknutím Ctrl+Shift+Enter (obr. 19.36). Nyní namísto použití rozsahu E2:H5 přidejte do vzorce příslušné prvky (obrázek 19.37).
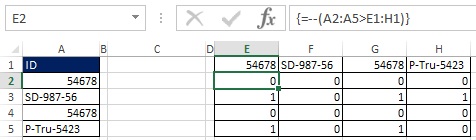

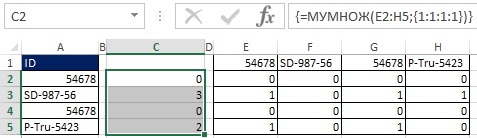
Rýže. 19:36. Výběrem rozsahu C2:C5 a zadáním funkce pole MULTIPLE získáte sloupec čísel, který vám řekne, kolik ID v seřazeném seznamu je vyšší než vybrané.
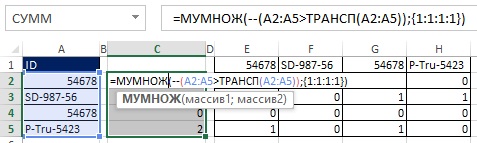
Rýže. 19:37. Namísto použití pomocného rozsahu E2:H5 jsou do vzorce přidány odpovídající prvky
Na Obr. Obrázek 19.38 ukazuje, jak můžete nahradit pole konstant fragmentem ROW($A$2:$A$5)^0.
Rýže. 19:39. Chcete-li se vypořádat s potenciálními prázdnými buňkami, měly by být všechny výskyty A2:A5 doplněny o kontrolu IF(A2:A5).<>"",A2:A5); funkce ROW takové sčítání nevyžaduje, protože funkce pracuje s adresou buňky, nikoli s jejím obsahem
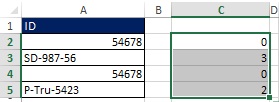
Protože konečný vzorec bude použit jinde, musíte všechny rozsahy nastavit jako absolutní (obrázek 19.40). Na Obr. Na obrázku 19.41 jsou zobrazeny výsledné hodnoty.
Rýže. 19:40. Rozsahy A2:A5 se změnily na absolutní
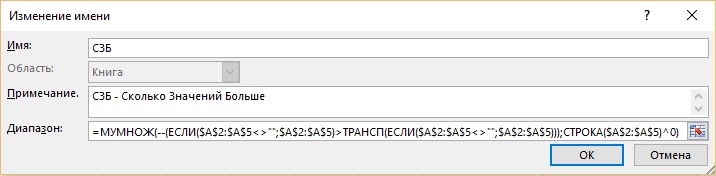
Protože tento prvek bude později použit dvakrát, můžete jej uložit pod konkrétním názvem. Jak je znázorněno v dialogovém okně (obr. 19.42), vzorec má název SZB - How Many Values Are Greater.
- Argument pole Funkce INDEX odkazuje na původní rozsah A2:A5.
- První funkce MATCH sdělí funkci INDEX relativní pozici prvku v poli A2:A5.
- Zatímco argument vyhledávací_hodnota Funkce MATCH je ponechána prázdná.
- Definovaný název (DSN) v argumentu viewed_array vám umožní nejprve přistupovat k prvku, který má hodnotu 0, poté 2 a nakonec 3.
- Nula v argumentaci typ_shody určuje přesnou shodu, což eliminuje potřebu odkazovat na duplikáty.
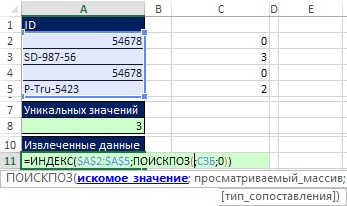
Rýže. 19,43. Spustíte vzorec pro extrakci a řazení dat v buňce A11. Argument vyhledávací_hodnota Funkce MATCH ponechte prozatím prázdné
Než vytvoříte argument vyhledávací_hodnota Funkce MATCH, zapamatujte si, co vlastně potřebujete. Existují tři jedinečná ID, která je třeba seřadit, takže v argumentu budete potřebovat tři čísla vyhledávací_hodnota jak se vzorec zkopíruje. Tato čísla vám umožní najít relativní pozici v poli A2:A5, což je to, co musíte poskytnout funkci INDEX:
- V buňce A11 funkce MATCH vrátí 0, což odpovídá relativní pozici 1 v rámci definovaného názvu SZB.
- Po zkopírování vzorce do buňky A12 by funkce MATCH měla vrátit číslo 2 a relativní pozici = 4 v rámci MSB.
- V buňce A13 by funkce MATCH měla vrátit 3 a relativní pozici = 2 v rámci MSB.
Když se zamyslíte nad argumentem, objeví se obrázek vyhledávací_hodnota při kopírování vzorce dolů by výzva měla odpovídat: „Uveďte minimální hodnotu v rámci konkrétního názvu SZB, který ještě nebyl použit.“ Jak je znázorněno na Obr. 19.44 prvek vzorce MIN(IF(END(MATCH($A$2:$A$5,A$10:A10,0)),MSB)) vrátí minimální hodnotu při kopírování vzorce dolů a přesně odpovídá na dotaz. Důvod, proč to funguje, je ten, že fragment UND(MATCH($A$2:$A$5,A$10:A10,0)) porovnává dva seznamy (viz ). Všimněte si rozšiřujícího se rozsahu A$10:A10 v argumentu viewed_array. V buňce A11 pomáhá kombinace UNM a MATCH extrahovat všechna jedinečná čísla z SZB a poskytnout je funkci MIN. Když vzorec zkopírujete dolů do buňky A12, ID, které bylo načteno v buňce A11, bude opět přítomno v rozšířeném rozsahu a bude opět nalezeno v rozsahu $A$2:$A$5. UND však vrátí hodnotu FALSE a hodnota 0 nebude extrahována ze SZB. Chcete-li to vidět, zadejte maticový vzorec na obrázku 19.44 stisknutím Ctrl+Shift+Enter a zkopírujte jej.
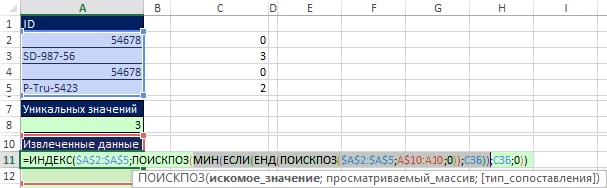
Rýže. 19,44. Prvek vzorce v argumentu vyhledávací_hodnota Funkce MATCH odpovídá požadavku: "Uveďte minimální hodnotu v rámci konkrétního názvu SZB, který ještě nebyl použit"
Na Obr. 19.45 ukazuje, že v argumentu viewed_array Druhá funkce MATCH rozšířila rozsah A$10:A10 na A$10:A11. Abyste pochopili, jak tento vzorec funguje, vyberte postupně jeho fragmenty a klikněte na F9 (obr. 19.46–19.49).
Rýže. 19:45. Rozšiřující se rozsah A$10:A11 nyní (v buňce A12) zahrnuje první ID (54678)
Rýže. 19,46. Kombinace UNM a druhé funkce MATCH poskytuje pole booleovských hodnot; dvě hodnoty FALSE vylučují hodnoty null z definovaného názvu SZB
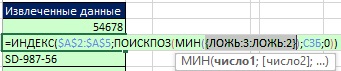
Rýže. 19,47. Nuly jsou odstraněny a zůstanou pouze čísla 3 a 2; číslo 2 je minimum, takže by mělo být extrahováno jako další

Rýže. 19,48. Funkce MIN vybere číslo 2; funkce MATCH nyní může najít správnou relativní pozici pro funkci INDEX
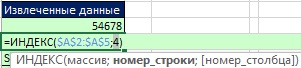
Rýže. 19,49. Funkce INDEX načte hodnotu 2, která odpovídá relativní čtvrté pozici ID v rozsahu A2:A5
Nyní, po návratu do buňky A11, můžete přidat další podmínku, aby prázdné buňky neovlivnily vzorec (obrázek 19.50).
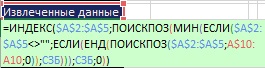
Rýže. 19:50. Uvnitř funkce MIN existují dvě podmínky; za prvé: "jsou buňky prázdné?", za druhé: "nebyla ještě použita hodnota?"
Na Obr. 19.51 ukazuje konečný vzorec. Přidala podmínku, která zajistí, že řádky v rozsahu A11:A15 zůstanou po extrahování seřazených jedinečných hodnot prázdné. Na Obr. Obrázek 19.52 ukazuje, co se stane, když buňka A3 zůstane prázdná. Náš doplněk pro kontrolu prázdných buněk fungoval.


Nebylo to jednoduché. Ale pokud jste dočetli až sem, doufám, že se vám to líbilo.
Jak se dalo očekávat, to, co šlo vyřešit v MS Excel, lze implementovat do Google Sheets. Ale četné pokusy vyřešit problémy pomocí vašeho oblíbeného vyhledávače vedly pouze k novým otázkám a téměř nulovým odpovědím.
Proto bylo rozhodnuto usnadnit život ostatním a oslavit sebe.
Krátce o tom hlavním
Aby Excel nebo tabulka (tabulka Google) pochopily, že to, co je napsáno, je vzorec, musíte do řádku vzorců vložit znak „=“ (obrázek 1).- alfanumerické (PÍSMENO = SLOUPEC; ČÍSLO = ŘÁDEK), například „A1“.
- styl R1C1, v systému R1C1 jsou řádky i sloupce označeny čísly.
Kde napíšeme „= vzorec“, například =SUM (A1:A10) a zobrazí se naše hodnota.
Obecný princip fungování vzorců RC je znázorněn na obrázku 2.

Obrázek 2
Jak je vidět z obrázku 3, hodnoty buněk jsou relativní k buňce, do které bude zapsán vzorec se znaménkem rovná se. Pro zachování estetického vzhledu vzorců obsahují symboly, které není třeba psát: RC = RC.

Obrázek 3
Rozdíl mezi obrázkem 2 a obrázkem 3 je v tom, že obrázek 3 je univerzální formulace, která není vázána na řádky a sloupce (podívejte se na hodnoty řádků a sloupců), což nelze říci o obrázku 2. Ale styl RC v tabulkovém procesoru se používá hlavně pro psaní javascriptových skriptů.
Typy odkazů (typy adresování)
Pro přístup k buňkám se používají odkazy, které se dodávají ve 3 typech:- Relativní odkazy (příklad, A1);
- Absolutní odkazy (příklad, $A$1);
- Smíšené odkazy (například $A1 nebo A$1, jsou napůl relativní, napůl absolutní).
Relativní odkazy
Relativní odkaz si "pamatuje", jak daleko (v řádcích a sloupcích) jste klikli RELATIVNĚ k pozici buňky, kam jste vložili "=" (posun v řádcích a sloupcích). Poté zatáhněte za úchyt automatického vyplňování a tento vzorec se zkopíruje do všech buněk, kterými jsme přetáhli.Absolutní odkazy
Jak bylo uvedeno výše, pokud přetáhnete značku automatického doplňování na vzorec obsahující relativní odkazy, tabulka přepočítá jejich adresy. Pokud vzorec obsahuje absolutní odkazy, jejich adresa zůstane nezměněna. Jednoduše řečeno, absolutní odkaz vždy ukazuje na stejnou buňku.Chcete-li relativní odkaz učinit absolutním, jednoduše vložte znak "$" před písmeno sloupce a adresu řádku, například $A$1. Více rychlý způsob- vyberte příslušný odkaz a jednou stiskněte klávesu „F4“, zatímco samotná tabulka přidá znak „$“. Pokud stisknete „F4“ podruhé, odkaz se změní na smíšený typ A$1, pokud potřetí - $A1, pokud počtvrté - bude odkaz opět relativní. A tak dále v kruhu.
Smíšené odkazy
Smíšené odkazy jsou napůl absolutní a napůl relativní. Znak dolaru se v nich objevuje buď před písmenem sloupce, nebo před číslem řádku. Toto je nejobtížněji pochopitelný typ odkazu. Například buňka obsahuje vzorec „=A$1“. Odkaz A$1 je relativní ke sloupci A a absolutní k řádku 1. Pokud přetáhneme úchyt automatického doplňování tohoto vzorce dolů nebo nahoru, budou odkazy ve všech zkopírovaných vzorcích ukazovat na buňku A1, to znamená, že se budou chovat jako absolutní. Pokud však táhneme doprava nebo doleva, odkazy se chovají jako relativní, to znamená, že tabulka začne přepočítávat svou adresu. Tímto způsobem budou vzorce generované automatickým dokončováním používat stejné číslo řádku ($1), ale hodnota písmen sloupce (A, B, C...) se změní.Podívejme se na příklad sečtení buněk s násobením určitým koeficientem.
Tento příklad předpokládá, že hodnota koeficientu je přítomna v každé vypočítané buňce (buňky D8, D9, D10...E8,F8...). (Obrázek 4).
Červené šipky ukazují směr, kterým značka natáhne vzorec, který se nachází v buňce C2. Ve vzorci si všimněte změny v buňce D8. Při natažení dolů se změní pouze číslo symbolizující čáru. Když se natáhnete doprava, změní se pouze sloupec.

Obrázek 4
Zjednodušme příklad pomocí znaku $ (obrázek 5).
Obrázek 5
Ale není vždy nutné zmrazit všechny sloupce a řádky, někdy použijete pouze řádek nebo pouze sloupec (obrázek 6).
Obrázek 6
O všech vzorcích si můžete přečíst na oficiálních stránkách support.google.com
Důležité: Data, která je třeba zpracovat ve vzorcích, by neměla být in různé dokumenty, to lze provést pouze pomocí skriptů.
Chyby ve vzorcích
Pokud vzorec napíšete špatně, budete na to upozorněni komentářem o syntaktické chybě ve vzorci (obrázek 7).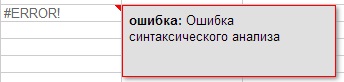
Obrázek 7
Chyby sice mohou být nejen syntaktické, ale také např. matematické, jako je dělení 0 (obrázek 7) a další (obrázek 7.1, 7.2, 7.3). Chcete-li zobrazit poznámku označující, k jaké chybě došlo, umístěte ukazatel myši na červený trojúhelník v pravém horním rohu chyby.
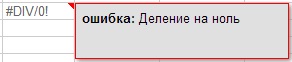
Obrázek 7.1
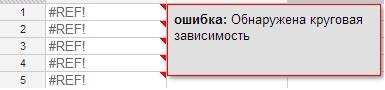
Obrázek 7.2
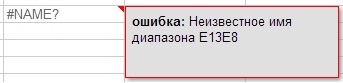
Obrázek 7.3
Aby se tabulka lépe četla, budou všechny buňky se vzorci zbarveny fialově.
Chcete-li vidět vzorce „živě“, musíte kliknout klávesová zkratka Ctrl + nebo vyberte Zobrazit > Všechny vzorce z horní nabídky. (Postavení 8).

Postavení 8
Jak se píšou vzorce
Ve formulaci vzorců v referenční knize a ve vzorcích, které se používají k práci tento moment, existují rozdíly. Spočívají v tom, že místo „čárky“, která se dříve používala v mnoha vzorcích, se již používá „středník“ (ke změnám došlo před více než šesti měsíci).Abyste viděli, na co vzorec na této stránce odkazuje (obrázek 9), musíte kliknout na řádek vzorců napravo od nápisu Fx (Fx se nachází pod hlavní nabídkou vlevo).
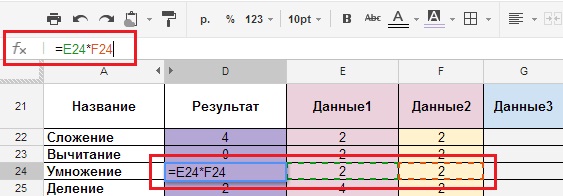
Obrázek 9
DŮLEŽITÉ: Aby vzorce fungovaly správně, musí být zapsány S latinskými písmeny. Ruské (cyrilice) „A“ nebo „C“ a latinské „A“ nebo „C“ pro vzorec jsou 2 různá písmena.
Vzorce
Aritmetické vzorce.
Nikdo vám samozřejmě nebude popisovat věčné operace sčítání, odčítání atd., ale pomohou vám pochopit úplné základy. Na několika příkladech pochopíte, jak v tomto prostředí fungují. Dokument, na který je odkaz uveden na konci článku, obsahuje všechny vzorce, my se ale zaměříme jen na screenshoty.Sčítání, odčítání, násobení, dělení.
- Popis: vzorce pro sčítání, odčítání, násobení a dělení.
- Typ vzorce: „Buňka_1+Buňka_2“, „Buňka_1-Buňka_2“, „Buňka_1*Buňka_2“, „Buňka_1/Buňka_2“
- Samotný vzorec: =E22+F22, =E23-F23, =E24*F24, =E25/F25.
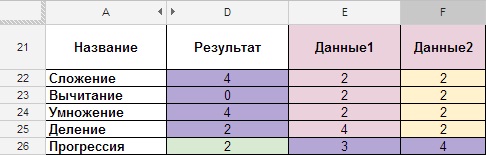
Obrázek 10
Postup.
- Popis: vzorec pro zvětšení všech následujících buněk o jednu (číslování řádků a sloupců).
- Typ vzorce: =Předchozí buňka + 1.
- Samotný vzorec: =D26+1
Obrázek 11
Zaokrouhlování.
- Popis: Vzorec pro zaokrouhlení čísla v buňce.
- Typ vzorce: =ROUND(buňka s číslem); počítadlo (kolik číslic má být zaokrouhleno za desetinnou čárkou).
- Samotný vzorec: =ROUND(E28,2).
Obrázek 12
Zaokrouhlení „ROUND“ probíhá podle matematických zákonů, pokud je za desetinnou čárkou číslo 5 nebo více, pak se celá část zvětší o jednu, pokud 4 nebo méně, zůstane nezměněno, zaokrouhlení lze provést i pomocí nabídky FORMÁT -> Čísla -> „1000, 12“ 2 desetinná místa (obrázek 13). Pokud potřebujete větší počet znaků, musíte kliknout na FORMÁT -> Čísla -> Přizpůsobená desetinná místa -> A zadat počet znaků.
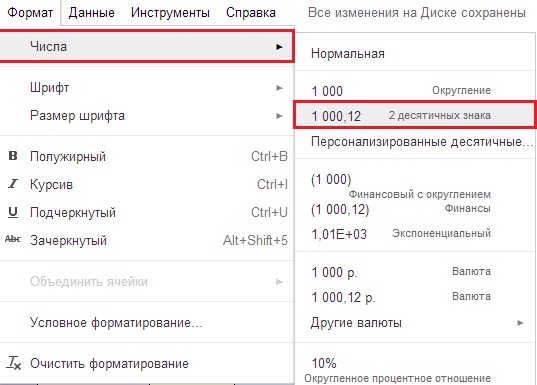
Obrázek 13
Součet, pokud buňky nejsou sekvenční.
Asi nejznámější funkce- Popis: sčítání čísel, která jsou v různých buňkách.
- Typ vzorce: =SUM(číslo_1; číslo_2;… číslo_30).
- Samotný vzorec: „=SUM(E30;H30)“ se zapisuje přes „;“ pokud různé buňky.
(Obrázek 14).
Součet, pokud jsou buňky po sobě jdoucí.
- Popis: sčítání čísel, která následují za sebou (postupně).
- Typ vzorce: =SUM(číslo_1: číslo_N).
- Samotný vzorec: =SUMA (E31:H31)" zapíšeme přes ":", pokud se jedná o spojitý rozsah.
- Máme počáteční data v oblasti buněk E31:H31 a výsledek v buňce D31 (obrázek 15).
Obrázek 15
Průměrný.
- Popis: Sečte rozsah čísel a vydělí počtem buněk v rozsahu.
- Typ vzorce: =PRŮMĚR (buňka s číslem nebo číslem_1; buňka s číslem nebo číslem_2; ... buňka s číslem nebo číslem_30).
- Samotný vzorec: =PRŮMĚR(E32:H32)
Obrázek 16
Samozřejmě jsou i další, ale jedeme dál.
Textové vzorce.
Z velkého množství textových vzorců, se kterými můžete s textem dělat cokoli, je podle mého názoru nejoblíbenější vzorec pro „slepování“ textových hodnot. Existuje několik možností pro jeho implementaci:Lepení textových hodnot (se vzorcem).
- Popis: „slepování“ textových hodnot (možnost A).
- Typ vzorce: =CONCATENATE(buňka s číslem/textem nebo text_1; buňka s číslem/textem nebo text_2; ..., buňka s číslem/textem nebo text_30).
- Samotný vzorec: =CONCATENATE(E36;F36;G36;H36).
S pomocí Google dokumenty, zaměstnanci se často zjišťují nebo se přes Google Forms sestavují sociologické průzkumy (jedná se o speciální formuláře, které lze vytvořit přes nabídku Vložit->Formulář. Po vyplnění formuláře se údaje zobrazí v tabulce. A dále různé vzorce slouží k práci s daty, např. ke slepení CELÉ JMÉNO.).
Obrázek 17
Slepování číselných hodnot.
- Popis: „lepení“ textových hodnot ručně, bez použití speciální funkce(Možnost B - ruční psaní vzorce, jakákoli složitost vzorce.).
- Typ vzorce: =buňka s číslem/textem 1&" "&buňka s číslem/textem 2&" "&buňka s číslem/textem 3&" "&buňka s číslem/textem 4 (" " - mezera, znaménko & znamená sloučení, všechny textové hodnoty jsou psány v uvozovkách „“).
- Samotný vzorec: =E37&" "&F37&" "&G37&" "&H37.
Obrázek 18
Sloučení číselných a textových hodnot.
- Popis: „slepování“ textových hodnot dohromady ručně, bez použití speciálních funkcí (možnost C - smíšený typ, vzorec libovolné složitosti).
- Typ vzorce: = „text_1“ &cell_1&“text_2“&cell_2&“text_3“&cell_3
- Důležité: veškerý text, který bude napsán v „“, bude pro vzorec nezměněn.
- Samotný vzorec: ="1 další" &E38&" s použitím "&F38&" jako US "&G38.
Přilepte text a číselné hodnoty.
Obrázek 19
LOGICKÉ A DALŠÍ
Přenos dat z libovolných listů stejného souboru.
Dostáváme se k nejzajímavějším, dle mého názoru, funkcím: LOGICKÉ A DALŠÍ.Jeden z nejnutnějších vzorců:
- Popis: přenos dat z libovolných listů stejného souboru (pro Excel můžete buď přenést z listu jednoho sešitu na jiný list téže knihy, nebo z listu jednoho sešitu na list jiné knihy).
- Typ vzorce: = „Název_listu“! buňka_1
- Samotný vzorec: =Data!A15 (Data jsou list, A15 je buňka na tomto listu).
Obrázek 20
Obrázek 20.1
Pole vzorců.
Většina tabulkových procesorů poskytuje dva typy maticových vzorců: multi-cell a single-cell.Tabulky Google rozdělují tyto typy do dvou funkcí: CONTINUE a ARRAYFORMULA.
Vzorce pole s více buňkami umožňují, aby vzorec vracel více hodnot. Můžete je použít, aniž byste o tom věděli, pouhým zadáním vzorce, který vrací více hodnot.
Vzorce pole s jednou buňkou umožňují psát vzorce pomocí vstupu pole, nikoli výstupu. Když zabalíte vzorec do funkce =ARRAYFORMULA, můžete předávat pole nebo rozsahy funkcím a operátorům, které obvykle berou pouze argumenty, které nejsou polemi. Tyto funkce a operátory budou aplikovány jeden po druhém na každý záznam v poli a vrátí nové pole s veškerým výstupem.
Pokud chcete problém prozkoumat podrobněji, měli byste navštívit support.google.
Mluvení jednoduchými slovy, pro práci se vzorci, které vracejí pole dat, je nutné je uzavřít do pole vzorců, aby se předešlo syntaktickým chybám.
Sečtení buněk s podmínkou IF.
Aby bylo možné pracovat s logickými vzorci, které obvykle obsahují velké množství dat, jsou umístěny v poli vzorců ARRAYFORMULA (vzorec).- Popis: sečtení buněk s podmínkou IF (vzorec SUMIF).
- Typ vzorce: = SUMIF('List'! rozsah; kritéria; 'List'! celkový_rozsah)
Úkolem je, jakou podobu bude mít fiskální účtenka po vytištění (stačí sečíst produkty 3 zákazníků a u každé položky zjistit celkový počet produktů)?
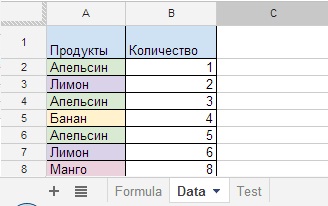
Obrázek 21
Počáteční data máme v datovém listu (obrázek 21) a výsledek na listu vzorců ve sloupci D (obrázek 22). Sloupce E, F, G zobrazují argumenty použité ve vzorci a sloupec H obecná forma vzorec, který je ve sloupci D a vypočítá výsledek.

Obrázek 22
Výše uvedený příklad ukazuje obecný vzhled vzorce „Sum If“ s jednou podmínkou, ale nejčastěji se používá vzorec „Sum IF“ (s více podmínkami).
Suma buněk IF, více podmínek.
Nadále zvažujeme problém s produkty na jiné úrovni.Večírek právě začíná a po zavolání vašich přátel si začnete uvědomovat, že alkoholu nebude dost. A je potřeba si ho koupit. Každý přítel si s sebou musí přinést silný nápoj. Musíte zjistit počet lahví piva, které musíte přinést, a zadat úkol svým přátelům.
- Popis: součet IF (s mnoha podmínkami).
- Typ vzorce: = SUMIF(‚Data‘! rozsah_1&‘Data‘! rozsah_2; kritéria_1&kritérium_2; ‚Data‘! celkový_rozsah).
- Samotný vzorec:=(ARRAYFORMULA(SUMIF((Data!E:E&Data!F:F);(B53&C53);Data!G:G)))

Obrázek 23
Řekněme, že na listu Vzorec by měl být v buňce B53 (kritérium_1 = Pivo) název nápoje a buňka C53 (kritérium_2 = 2) je počet přátel, kteří přinesou Pivo. V důsledku toho bude buňka D53 obsahovat výsledek, že potřebujeme koupit 15 lahví piva. (Obrázek 23.1), to znamená, že vzorec určí množství podle dvou kritérií – piva a počtu přátel.
Obrázek 23.1
Pokud je takových pozic více, řádky 16 a 21 (obrázek 24), pak se počet bublin ve sloupci G sečte (obrázek 24.1).
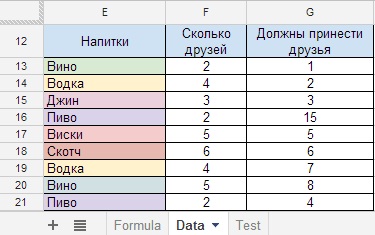
Obrázek 24
Celkový:
Obrázek 24.1
Nyní uveďme zajímavější příklad:
Ha... večírek pokračuje a vy si vzpomenete, že potřebujete dort, ale ne jednoduchý, a super - mega dort s různým kořením, který je, jako štěstí, navíc zašifrovaný digitálními symboly. Úkolem je nakoupit koření v potřebném počtu sáčků od každého koření. Kuchař zašifroval požadované množství do tabulky (obrázek 25.1), sloupců A a B (výpočty provádíme v sousedních sloupcích).Každé koření má své sériové číslo: 1,2,3,4. (Obrázek 25).

Obrázek 25
Naším úkolem je spočítat počet opakujících se hodnot, v našem případě se jedná o čísla od 1 do 4 ve sloupci B a určit, jaké procento tvoří každé z koření.
- Popis: počítání identických číslic ve velkých polích za dalších podmínek.
- Typ vzorce: COUNT IF('Vzorec'! rozsah_A55: A61+'Vzorec'! rozsah_B55:B61; PodmínkaA"Koření"+Číslo podmínkaB od 1 do 4"; List"Vzorec"! rozsah_B55:B61)/Číslo podmínkaB od 1 až 4")
- Samotný vzorec: =((ARRAYFORMULA(SUMIF("Formula"!$A$55:$A$61&"Formula"!$B$55:$B$61; $F$55&$E59;"Formula"!$B$55: 61 $ B$)))/E59 $)
- Popis: Vypočítejte procento koření.
- Typ vzorce: Množství*100 %/celkové_množství
- Samotný vzorec: =F58*$G$56/F$56
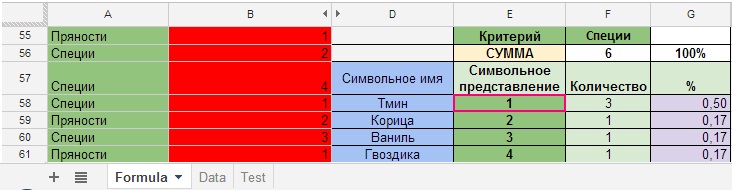
Obrázek 25.1
Nakonec máme součet opakování a procenta.
Abyste vzorec napsali správně, musíte plně rozumět tomu, co MÁTE, co CHCETE ZÍSKAT a v jaké podobě. K tomu možná budete muset změnit typ počátečních dat.
Přejděme k dalšímu příkladu
Počítání hodnot ve sloučených buňkách.
Pokud vzorce používají hodnoty ve „sloučených buňkách“, je označena první buňka pro sloučená data, v našem případě je to sloupec F a buňka F65 (obrázek 26)
Obrázek 26.
A konečně se dostáváme k těm nejhorším vzorcům.
Spočítá počet čísel v seznamu argumentů.
Existuje několik typů takových výpočtů, jsou vhodné pro velké tabulky, ve kterých je třeba počítat počet stejných slov nebo počet čísel. Ale když správné pochopení Tyto vzorce lze použít k takovým zázrakům, jako je například: počítání slov bez zohlednění výjimek. Příklady níže.- Popis: Spočítá počet buněk obsahujících čísla bez textových proměnných.
- Typ vzorce: COUNT(hodnota_1; hodnota_2; … hodnota_30)
- Samotný vzorec: =POČET(E45;F45;G45;H45)
Obrázek 27.
Buňky obsahující text a čísla se také nepočítají.
Obrázek 27.1.
Počítání počtu buněk obsahujících čísla s textovými proměnnými.
- Popis: Spočítá počet buněk obsahujících čísla s textovými proměnnými.
- Typ vzorce: COUNTA(hodnota_1; hodnota_2; ... hodnota_30)
- Samotný vzorec: =COUNTA(E46:H46)
Obrázek 28.
Vzorec také počítá buňky obsahující pouze interpunkční znaménka, tabulátory, ale nepočítá prázdné buňky.
Obrázek 28.1
Dosazení hodnot za podmínek.
- Popis: záměna hodnot za podmínek.
- Typ vzorce: "=IF(AND((Podmínka1);(Podmínka2)); Výsledek je 0, pokud jsou splněny podmínky 1 a 2; pokud splněny nejsou, pak je výsledek 1)“
- Samotný vzorec: "=IF(AND((F73=5);(H73=5));0;1)"
Obrázek 29.
Obrázek 29.1
Pojďme si příklad zkomplikovat.
Spočítejte počet buněk, do kterých jsou zapsány časové rámce, aniž byste brali v úvahu slova „automatická odpověď“, „zaneprázdněno“, „-“.
- Typ vzorce: "=COUNTA(Rozsah_A)-COUNTIF(Rozsah_A; "automatická odpověď")-COUNTIF(Rozsah_A; "-")-COUNTIF(Rozsah_A; "zaneprázdněn")"
- Samotný vzorec: =COUNTA($E74:$H75)-COUNTIF($E74:$H75; "automatická odpověď")-COUNTIF($E74:$H75; "-")-COUNTIF($E74:$H75; "zaneprázdněn ")

Obrázek 30
Takže jsme se dostali na konec našeho malého vzdělávacího programu o vzorcích v Google SpreadSheet a já pevně doufám, že jsem osvětlil některé aspekty analytické práce se vzorci.
Vzorce, abych byl upřímný, byly doslova těžce vydělané. Každý z nich vznikal dlouhou dobu. Doufám, že se vám můj článek a příklady v něm uvedené líbily.
A nakonec jako dárek. A ať mi vývojáři odpustí!
Formule "DOCUMENT KILLER".
Pokud potřebujete navždy skrýt dokument před zvědavýma očima, pak je tento vzorec pro vás.Samotný vzorec: "=(ARRAYFORMULA(SUMIF($A:$A&$C:$C;$H:$H&F$2; $C:$C)))“. $H:$H řídí šíření vzorce. Po spuštění vzorce (obrázek 31) se v buňkách pod ním začne reprodukovat následující funkce CONTINUE(buňka; řádek; sloupec).

Obrázek 31
Vzorec prochází celým sloupcem vzorce. Abyste mohli zabít dokument, musíte se trochu snažit, vytvořit N počet buněk a napsat vzorec do prvních buněk z N počtu sloupců. Všechno! Nikdo jiný nemůže dokument opravit ani zkontrolovat!
Zde je to, co stránka nápovědy Google říká o pracovní zátěži a omezeních –
psaní matematických vzorců
Obecná charakteristika a spuštění editoru vzorců
Psaní a úpravy vzorců ve Wordu se provádí pomocí editoru vzorců Microsoft Equation 3.0, který obsahuje asi 120 šablon. Umožňuje vkládat do dokumentu matematické symboly a výrazy, včetně zlomků, mocnin, integrálů atd. Při psaní vzorce se na jeho různé součásti automaticky aplikují příslušné styly (zmenšená velikost písma pro exponenty, kurzíva pro proměnné atd.).
Příklad. Spuštění editoru vzorců.
1. Umístěte kurzor na místo, kde zadáváte a upravujete vzorec.
2. V nabídce Vložit dáme příkaz Objekt…, otevřete dialogové okno Vložení objektu.
3. Na kartě Stvoření v terénu Typ objektu: Vyberme MicrosoftEquation3.0.
4. Klepněte na tlačítko OK.
V důsledku toho se otevře dialog pro práci s editorem vzorců.
Chcete-li spustit editor vzorců a upravit existující vzorec, poklepejte na pole vzorce.
Dokončení úprav nebo psaní vzorce se provádí mimo pole pro zadání vzorce.
Rozhraní editoru vzorců
Po spuštění editoru vzorců se otevře okno editoru vzorců, které má vlastní panel nástrojů. Tento panel se skládá ze dvou řad tlačítek:
přístup ke znakovým sadám,
přístup k sadám šablon.
Do vzorce můžete z klávesnice zadávat písmena ruské a latinské abecedy a také znaky jednoduchých matematických operací (+, -, /).
Řádek tlačítek pro přístup k sadám symbolů umožňuje zadávat do vzorce matematické symboly (operační znaky a písmena řecké abecedy).
Horní řádek panelu nástrojů obsahuje následující znakové sady zleva doprava:
Symboly vztahů;
intervaly a elipsy;
matematické rozdíly;
Provozní značky;
symboly šipek;
Symboly teorie množin;
Logické znaky;
různé symboly;
Řecká písmena.
Pomocí šablon panelu nástrojů můžete do vzorce vložit symboly řady matematických operací a určit symboly pro integrály, součty a součiny. Kromě toho šablony umožňují určit formu matematického výrazu (zlomek, stupeň, index, matice atd.) pro následné zadávání matematických symbolů do obrobku získaného pomocí šablony.
Následující sady šablon jsou umístěny ve spodním řádku panelu nástrojů zleva doprava:
Šablony omezení;
Vzory zlomků a kořenů;
Tvorba dolních a horních indexů;
Integrály;
Podtržení a podtržení;
označené šipky;
Díla a vzory teorie množin;
Maticové šablony.
Při psaní symbolů vzorců má vstupní kurzor podobu znaků nebo. Znak zadaný do vzorce je umístěn vpravo nebo vlevo od svislé čáry a nad vodorovnou čárou vstupního kurzoru.
Záznam a úprava vzorců
Při psaní a úpravě vzorce lze zadání dalšího znaku na jeho konci provést v hlavním vstupním řádku - místo zadaného znaku je automaticky označeno štěrbinou (obdélník s tečkovanou čarou). Pokud potřebujete zadat symbol pro součet, integrál nebo jinou složitou vzorcovou strukturu, vyberte pomocí myši příslušnou ikonu z příslušné sady šablon.
Do středu štěrbiny lze vložit polotovary získané pomocí šablon. Tímto způsobem se vytvářejí vícekrokové vzorce.
Úprava existujícího vzorce zahrnuje odstranění jednotlivých prvků a zavedení nových pomocí editoru vzorců.
Příklad. Psaní fragmentu vzorce.
Představme si fragment vzorce jako:  .
.
1. Kliknutím myši otevřete podnabídku se sadou šablon množství.
2. Klikněte na šablonu součtu s horním a dolním limitem (šablona zcela vpravo je v horním řádku).
Výsledkem je, že se v okně úpravy vzorce objeví mezera jako tato: .
3. Zadejte požadovaný symbol, číslo nebo výraz do každého ze slotů, nejprve tam umístěte vstupní kurzor a fragment vzorce získá požadovaný tvar.
Příklad. Odstranění prvku vzorce.
1. Kliknutím myši vyberte prvek, který chcete odstranit.
2. Stiskněte klávesu
Pokud je prvek vzorce součástí fragmentu vytvořeného pomocí šablony, pak po jeho odstranění vstupní slot. Vstupní slot lze odstranit pouze společně se šablonou, ke které patří.
V některých případech může být po smazání prvků vzorce narušeno grafické znázornění některých jeho zbývajících prvků. Chcete-li obnovit normální vzhled vzorce, měli byste spustit příkaz Překreslit Jídelní lístek Pohled.
Příklad. Vkládání nových prvků do vzorce.
1. Umístěte vstupní kurzor na požadované místo ve vzorci.
2. Zadejte požadovanou sekvenci znaků.
3. V případě potřeby použijte šablonu k vložení polotovaru a poté vyplňte jeho otvory potřebnými symboly.
Příklad. Psaní vzorce se zlomkovou čárou.
 .
.
1. Umístěte kurzor na místo vzorce.
3. Do slotu rámečku pro zadání vzorce pomocí klávesnice zadejte začátek vzorce „ 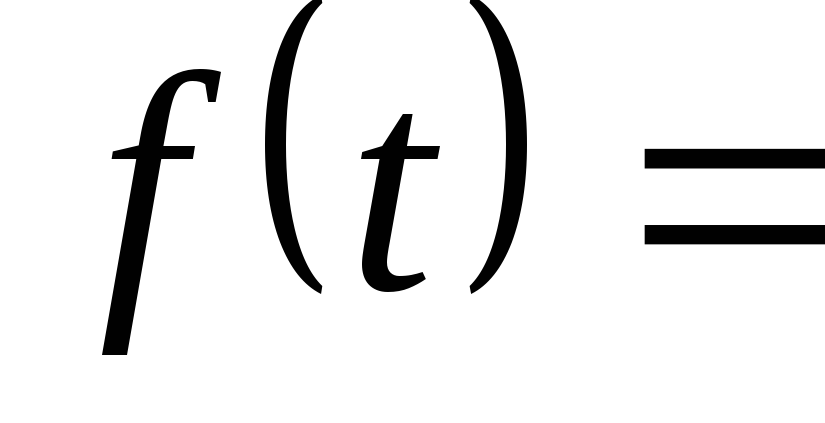 ».
».
4. V sadě Zlomkové a kořenové vzory klikněte na šablonu
(šablona vlevo nahoře).
Tím vložíte šablonu se dvěma sloty do čitatele a jmenovatele zlomku.
5. Do pole jmenovatele zadejte výraz 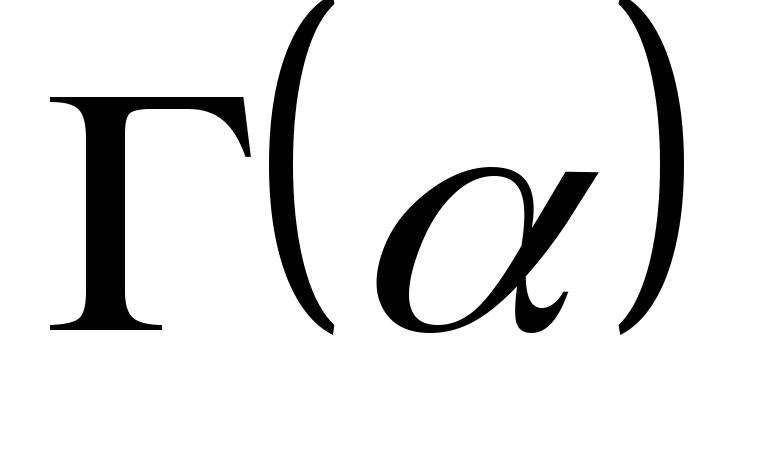 a ve slotu pro čitatel -
a ve slotu pro čitatel -  .
.
6. V sadě šablon Vytváření dolních a horních indexů Vyberme šablonu, která určuje vytvoření pravého horního indexu.
7. Do slotu, který se objeví, zadejte výraz pro stupeň „n-1“.
8. Umístěte vstupní kurzor na konec již napsané části vzorce.
9. V sadě šablon Vytváření dolních a horních indexů vyberte šablonu.
10. Do prázdného pole, které se objeví, zadejte symbol „ E", a do slotu pravého horního indexu zadáme výraz stupně "- nt».
Klepnutím mimo rámeček vzorce zavřete dialogové okno pro úpravu vzorce.
Zápis maticových vzorců
Chcete-li zapsat vzorce maticového typu do spodního řádku panelu nástrojů, použijte sadu Maticové šablony.
Příklad. Psaní vzorce se složenými závorkami.
Zvažte napsání vzorce ve tvaru: 
2. Otevřete okno editoru vzorců.
3. Do slotu rámečku pro zadání vzorce z klávesnice zadejte „ y= ».
4. V sadě Šablony omezení Klikněte na šablonu.
Tím se vloží složená závorka se štěrbinou napravo od ní.
5. Umístěte vstupní kurzor do pojmenovaného slotu.
6. V sadě Šablony matic vyberte šablonu: .
Tím se slot napravo od složené závorky převede na dva sloty nad sebou. To způsobí úměrné zvětšení velikosti samotné složené rovnátka.
7. Zadejte odpovídající výrazy vzorce do horní a dolní pozice.
8. Klepnutím zavřete dialogové okno vytváření vzorce.
Příklad. Psaní maticového vzorce.
Podívejme se na příklad zápisu vzorce pro determinant 3. řádu:
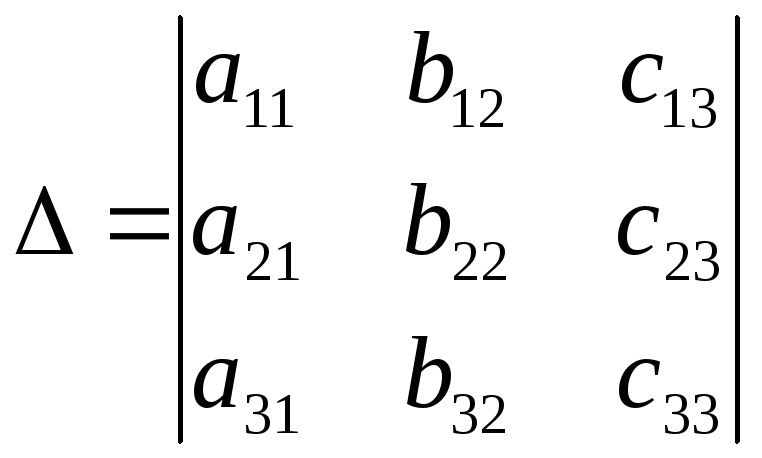 .
.
1. Umístěte vstupní kurzor na místo vzorce.
2. Otevřete okno editoru vzorců.
3. Do slotu rámečku pro zadání vzorce z klávesnice zadejte „=“.
4. Otevřeme sadu Maticové šablony a vyberte šablonu:
5. Otevře se dialogové okno Matice. Nastavíme počet řádků a počet sloupců matice.
6. Kliknutím na levou a pravou stranu maticového obrázku v okně nastavte svislé čáry podél okrajů matrice.
7. Ve skupině spínačů Zarovnání sloupců vyberte přepínač Na střed.
8. Ve skupině přepínačů Line Alignment vyberte přepínač Po hlavní linii. Klepněte na tlačítko OK.
V důsledku toho bude vložen maticový polotovar se třemi řádky a třemi sloupci a svislými čarami po stranách.
9. Do prvního slotu prvního řádku zadejte symbol „ A».
10. V sadě šablon Vytváření dolních a horních indexů vyberte šablonu, která určuje vytvoření pravého dolního indexu.
11. Zadáme do něj "11".
12. Stejným způsobem vyplníme zbývající sloty.
13. Klepnutím mimo rámeček vzorce zavřete dialogové okno vytváření vzorce.

Změna velikosti a přesouvání vzorce
Změna velikosti a přesunutí vzorce se provádí přímo v hlavním okně dokumentu aplikace Word. Před provedením kterékoli z těchto akcí musíte vzorec vybrat kliknutím myši.
Příklad. Změna velikosti vzorce.
1. Kliknutím myši vyberte vzorec.
2. Umístěte ukazatel myši na jednu z osmi značek zvýrazněného rámečku a přetáhněte jej, dokud nedosáhnete požadované velikosti.
Pokud se rozměry vzorce neúměrně změní, může dojít k narušení vzájemné polohy prvků.
Chcete-li změnit měřítko obrázku vzorce, musíte vzorec zvýraznit a vybrat Upravit | Objekt | Formule | OTEVŘENO. Poté z nabídky vyberte příslušnou stupnici (od 25 % do 400 %) Pohled.
Příklad. Přesouvání vzorce.
1. Kliknutím myši vyberte vzorec.
2. Přesuňte ukazatel myši na vzorec tak, aby měl tvar šipky směřující doleva.
3. Klikněte levým tlačítkem myši a přetáhněte vzorec na požadované místo v dokumentu.
4. Chcete-li změnit vodorovnou polohu vzorce, nastavte příkaz Odstavec… Jídelní lístek Formát a nastavte požadované hodnoty pro parametry odstavce pomocí vzorce.
Text Textový procesor má několik vestavěných programů, které implementují různé objekty do vytvořeného dokumentu. Jsou přístupné přes Vložit/Objekt.... Podívejme se na dva nejoblíbenější z nich: stavitel grafů a editor vzorců.
Stavební grafy
Aplikace slouží k vytváření diagramů "Microsoft Graph Chart".
Vyberte buňky v tabulce, jejichž data se použijí k vytvoření grafu. Obsah horního řádku a levého sloupce vybrané oblasti se používá k označení značek na souřadnicových osách.
Přes menu Vložit/Objekt.../Vytvořit v seznamu "Typ objektu" vyberte "Microsoft Graph Chart", za kterou se zobrazí tabulka s údaji a diagramem.
Nastavit štítky v tabulce: štítky z prvního řádku tabulky, které se objeví, se používají k označení vodorovné osy a z prvního sloupce - pro legendu. Legenda je vysvětlující obrázek napravo od diagramu.
Upravte diagram. Chcete-li to provést, klikněte pravým tlačítkem myši na upravovaný prvek diagramu - zobrazí se nabídka pro jeho úpravu.
Ukončete Microsoft Graph kliknutím do hlavního okna mimo graf.
Přesuňte diagram na požadované místo v dokumentu a upravte jeho rozměry.
Příklad
Vytvořme diagram znázorňující dynamiku příjmů (viz tabulka výše). Chcete-li to provést, vyberte v tabulce interval A2:F5 a načtěte „Microsoft Graph“. Upozorňujeme, že tento rozsah zahrnuje řádek s názvy měsíců a sloupec s názvy měst. Používají se pro popisky vodorovných os a legend.
Pokud potřebujete graf upravit, klikněte pravým tlačítkem do grafu a vyberte položku nabídky „Možnosti grafu“. Otevře se okno Možnosti grafu, které vám umožní provádět většinu oprav. Chcete-li například nastavit štítky na vodorovné ose, musíte otevřít kartu „Osy“ a zaškrtnout políčko „Osa X (kategorie)“ a štítek „Automaticky“. Pokud potřebujete změnit typ grafu, měli byste vybrat položku nabídky "Typ grafu".
Chcete-li nastavit vertikální orientaci štítků pod osou X, klikněte pravým tlačítkem myši na kterýkoli štítek, vyberte nabídku "Formát osy" a na kartě "Zarovnání" nastavte vertikální orientaci.
Pokud je aktivní objekt "Microsoft Graph", přejděte do nabídky Data/Řádky tvoří sloupce, pak se na ose X zobrazí data ze sloupců tabulky.
Všechny akce pro úpravu grafu lze provádět prostřednictvím lišty nabídek, která za běhu aplikace Microsoft Graph nahrazuje hlavní nabídku.
Poslední fází úpravy diagramu je změna jeho velikosti a umístění na požadované místo na stránce.
Práce s editorem vzorců
Editor vzorců "Microsoft Equation" je program, který se instaluje během instalace Word editor na žádost uživatele. Editor má velkou sadu matematické symboly a umožňuje zobrazit poměrně složité vzorce. Na rozdíl od editoru TEX, ve kterém je vzorec nejprve zakódován a poté reprodukován speciální program, "Microsoft Equation" vám umožňuje vidět vzorec tak, jak je napsán. Po zaznamenání vzorce lze jeho rozměry měnit jako běžný výkres.
Chcete-li napsat vzorec, musíte umístit kurzor na správné místo a přejít do nabídky Vložit/Objekt/Microsoft Equation 3.0. V tomto případě by se měl objevit rámeček pro zadání vzorce a panel editoru vzorců obsahující dvě řady tlačítek. Určuje horní řada tlačítek paleta symbolů, dolní - paleta šablon. Vzorec můžete doplnit kliknutím mimo vstupní pole.
Obecné pořadí množiny vzorců spočívá ve výběru požadovaného prvku v panelu editoru vzorců a jeho specifikaci v nabídce, která se objeví. Běžné znaky se zadávají z klávesnice do určených polí. Při přechodu z jednoho pole do druhého a při zadávání nových polí musíte sledovat polohu a velikost kurzoru. Například kurzor pro zlomek je větší než jeho čitatel nebo jmenovatel. Tímto způsobem se zobrazí prostor pro zadání dalšího znaku.
Vkládání mezer ve vzorcích nelze provést pouhým stisknutím příslušné klávesy. V Paletě znaků je k dispozici několik typů prostorů. Pokud musíte často vkládat mezery, je vhodné použít kombinace kláves uvedené v tabulce.
Zarovnání vzorce může být vyžadováno například po změně jeho velikosti, a to navzdory skutečnosti, že ve většině případů editor vzorců sám zarovná vzorec vzhledem k řádku, na kterém je zapsán. Chcete-li zarovnat celý vzorec nebo jeho část, musíte vyvolat vzorec pro úpravu dvojitým kliknutím myši, vybrat část, kterou chcete zarovnat, a stisknout kombinaci klávesy Ctrl a jedné z kurzorových kláves požadovaný počet opakování , v závislosti na směru zarovnání. Každé kliknutí posune vybranou část o 1 pixel.
Kontrolní otázky
- Jak se dostanete k vestavěným programům, které implementují různé objekty do vytvořeného dokumentu?
- Jakou aplikaci používáte k vytváření diagramů?
- Jak si vybrat grafickou aplikaci?
- Jak sestavit diagram?
- Co je to legenda v grafu?
- Jak nastavit popisky pro značení vodorovné osy a legendy?
- Jak upravit diagram?
- Jaké jsou možnosti editoru vzorců?
- Jak napsat vzorec v dokumentu?
- Jaké je obecné pořadí sady vzorců?
- Jak vložit mezeru do vzorce?
- Jak zarovnat vzorec?